\"점검 안내: 오전 2시~6시 서비스 중단\" — 2026년에도 이런 공지를 보내야 할까? Rolling, Blue-Green, Canary 배포 전략의 원리부터 AWS 구현, 실전 사례까지. 서비스를 멈추지 않고 업데이트하는 방법을 알아본다.
코어닷투데이2026-02-0465분
들어가며: "점검 안내: 오전 2시~6시 서비스 중단"
새벽 2시. 서버실 형광등 아래에서 엔지니어 세 명이 긴장한 얼굴로 모니터를 바라본다. 한 명이 "배포 시작합니다"라고 말하고, 서버를 내린다. 그 순간부터 시계와의 싸움이 시작된다. 4시간 안에 새 버전을 올리고, 테스트하고, 문제가 없는지 확인해야 한다. 만약 뭔가 잘못되면? 다시 이전 버전으로 되돌려야 한다. 시간은 오전 6시까지밖에 없다.
2026년인데, 왜 아직도 이런 일이 벌어질까?
이유는 간단하다. 배포 = 서비스 중단이라는 공식을 깨지 못했기 때문이다.
하지만 넷플릭스는 하루에 수천 번 배포한다. 아마존은 평균 11.7초마다 코드를 프로덕션에 올린다. 사용자는 전혀 눈치채지 못한다. 어떻게?
답은 배포 전략(Deployment Strategy)에 있다. 이 글에서는 서비스를 한 번도 멈추지 않고 업데이트하는 핵심 기술 — Rolling, Blue-Green, Canary 배포 — 의 원리부터 실전 구현까지 풀어본다.
11.7초Amazon 평균 배포 간격2024년 기준, 하루 ~7,400회
23분배포 장애 시 평균 복구 시간DORA 리포트 2024, Elite 팀 기준
$400K시간당 다운타임 비용Gartner, 중견 기업 평균
1. 문제 정의: 배포가 두려운 이유
전통적 배포의 공포
전통적인 배포(Recreate 또는 Big Bang 배포)는 단순하다. 기존 서버를 전부 내리고, 새 버전을 전부 올린다. 마치 가게를 닫고, 인테리어를 바꾸고, 다시 여는 것과 같다.
v1 전체 중지
→
다운타임 발생
→
v2 전체 시작
이 방식의 문제점은 명확하다:
다운타임: 서버를 내리는 순간부터 새 버전이 안정화될 때까지, 사용자는 서비스를 사용할 수 없다.
롤백 공포: 새 버전에 버그가 있으면? 다시 이전 버전으로 되돌려야 하는데, 그것도 또 다운타임이 필요하다.
데이터 불일치: 배포 중 DB 스키마가 바뀌면, 이전 버전으로 되돌리는 것 자체가 불가능할 수 있다.
심리적 압박: "이번 배포 실패하면 매출 손실이 얼마야?" — 이 질문이 엔지니어를 새벽에 출근하게 만든다.
다운타임의 실제 비용
💡
다운타임 비용 계산: Gartner에 따르면 IT 다운타임의 평균 비용은 분당 $5,600이다. 1시간이면 약 $336,000. 하지만 이건 평균이다. 대형 이커머스의 경우 분당 손실이 $10,000을 넘기도 한다. 서비스를 1시간 내렸다 올리는 "간단한 점검"이 실제로는 수억 원의 비용을 만든다.
현대 소프트웨어 개발에서 배포 전략은 "선택"이 아니라 생존 전략이다. 그래서 업계는 수십 년에 걸쳐 서비스를 멈추지 않고 업데이트하는 방법을 발전시켜 왔다.
Rolling 배포는 가장 직관적인 무중단 배포 방식이다. 서버(인스턴스)를 한 대씩 또는 몇 대씩 순서대로 교체한다. 전체를 한꺼번에 내리지 않으므로, 나머지 서버들이 트래픽을 계속 처리한다.
비유하자면: 도로 위의 차선을 하나씩 보수하는 것과 같다. 전체 도로를 폐쇄하지 않고, 한 차선씩 작업하면서 나머지 차선으로 교통을 유지한다.
동작 원리
서버 4대가 v1을 실행하고 있다고 가정하자.
Step 1서버 A를 로드밸런서에서 제거 → v2로 업데이트 → 헬스 체크 통과 → 다시 연결
Step 2서버 B를 로드밸런서에서 제거 → v2로 업데이트 → 헬스 체크 통과 → 다시 연결
Step 3서버 C를 로드밸런서에서 제거 → v2로 업데이트 → 헬스 체크 통과 → 다시 연결
Step 4서버 D를 로드밸런서에서 제거 → v2로 업데이트 → 헬스 체크 통과 → 다시 연결. 배포 완료!
핵심 포인트
배포 중에는 v1과 v2가 동시에 존재한다. 이것이 Rolling 배포의 가장 큰 특징이자 주의점이다.
예를 들어, 쇼핑몰 API에서 v1은 장바구니 응답에 totalPrice를 보내고, v2는 totalAmount로 필드명을 바꿨다면? Step 2 시점에는 서버 A(v2)와 서버 B~D(v1)가 공존한다. 프론트엔드가 두 형식을 모두 처리하지 못하면, 일부 사용자에게 에러가 발생한다.
이것을 호환성(backward compatibility) 문제라고 하며, Rolling 배포에서 가장 신경 써야 하는 부분이다.
장단점
Rolling 배포 특성
장점다운타임 없음. 추가 서버 비용 최소. 대부분의 오케스트레이터(ECS, K8s)가 기본 지원. 점진적 교체로 리스크 분산.
단점배포 중 v1/v2 공존 → 호환성 관리 필요. 전체 배포 완료까지 시간이 오래 걸림. 롤백 시 다시 역순으로 교체해야 함.
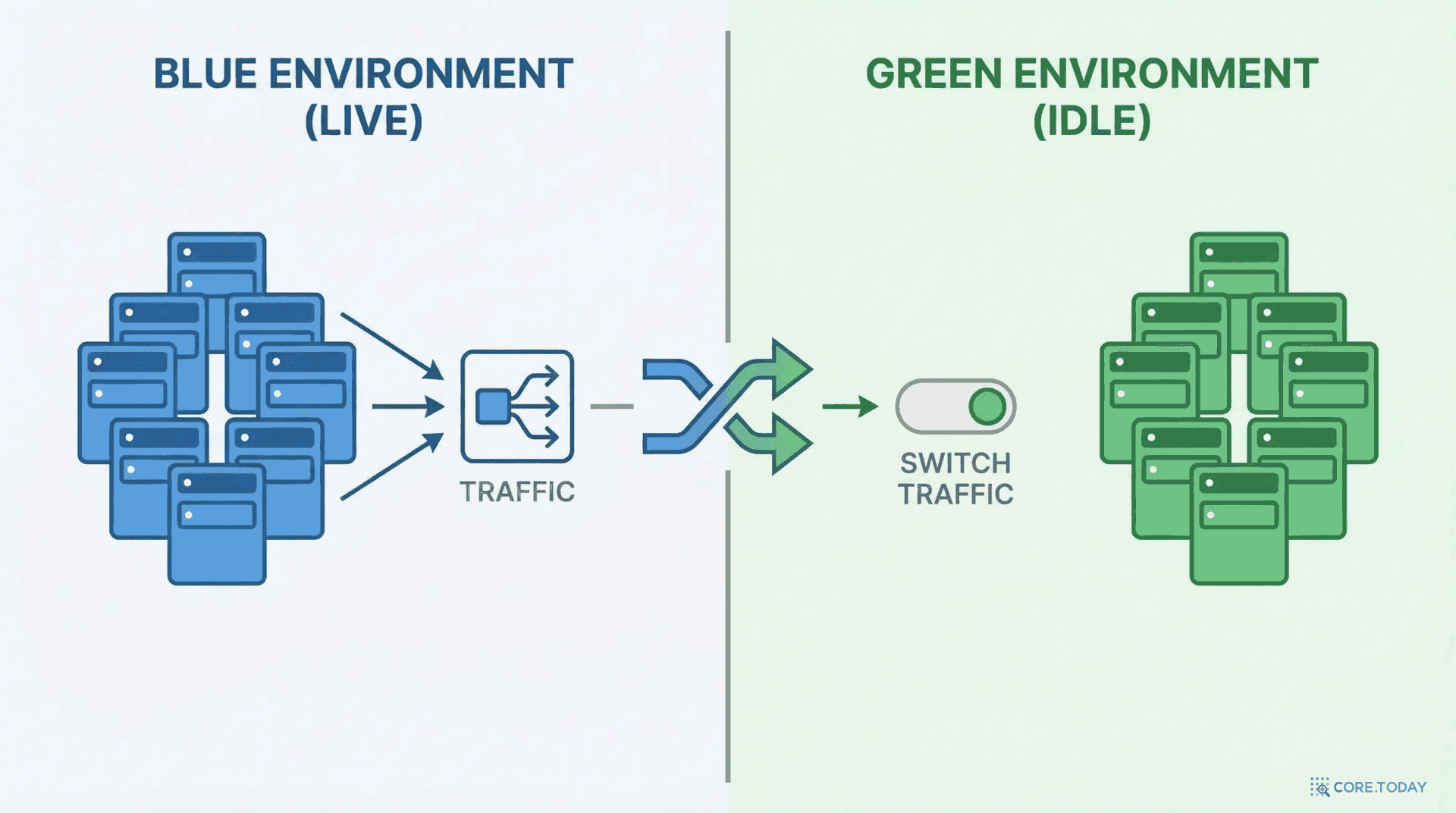
Blue-Green 배포는 완전히 동일한 두 세트의 프로덕션 환경을 유지하는 전략이다. 한쪽(Blue)은 현재 라이브 버전, 다른 쪽(Green)은 새 버전을 준비하는 용도다.
비유하자면: 연극 무대가 두 개인 극장이다. 한쪽 무대에서 공연이 진행되는 동안, 다른 무대에서 다음 공연을 세팅한다. 준비가 끝나면 관객석을 180도 돌려서 새 무대를 보여준다. 관객은 전환이 일어나는 순간을 거의 느끼지 못한다.
동작 원리
Blue (v1) — 라이브
←
로드밸런서 / 라우터
✕
Green (v2) — 대기
준비Green 환경에 새 버전(v2)을 배포한다. Blue(v1)에는 아무 영향 없이, 사용자는 정상적으로 서비스를 이용한다.
테스트Green 환경에서 내부 테스트(smoke test, 통합 테스트)를 실행한다. 문제가 발견되면 Green만 수정 — 라이브에 영향 없음.
전환로드밸런서(또는 DNS)를 Blue → Green으로 전환한다. 이 순간 모든 트래픽이 v2로 이동. 전환 시간: 수 초.
정리Blue 환경을 유지한 채 모니터링. 문제 발생 시 즉시 Blue로 롤백. 안정되면 Blue를 다음 배포용으로 전환.
왜 "순간 전환"이 가능한가
핵심은 트래픽 라우팅의 분리다. 서버를 내리는 것이 아니라, 로드밸런서가 가리키는 방향만 바꾼다. 라우팅 변경은 밀리초 단위로 일어나므로, 사용자 입장에서 다운타임은 0에 가깝다.
Blue-Green 전환 예시 (AWS ALB)
hljs language-bash
# Green 타겟 그룹으로 트래픽 100% 전환
aws elbv2 modify-listener \
--listener-arn arn:aws:elasticloadbalancing:ap-northeast-2:...:listener/... \
--default-actions Type=forward,TargetGroupArn=arn:aws:...:targetgroup/green-tg/...
# 문제 발생 시 즉시 Blue로 롤백
aws elbv2 modify-listener \
--listener-arn arn:aws:elasticloadbalancing:ap-northeast-2:...:listener/... \
--default-actions Type=forward,TargetGroupArn=arn:aws:...:targetgroup/blue-tg/...
장단점
Blue-Green 배포 특성
장점제로 다운타임. 즉시 롤백 가능(수 초). 새 버전을 라이브 전에 충분히 테스트 가능. v1/v2 공존 문제 없음(순간 전환).
단점인프라 비용 2배 (두 세트 유지). DB 스키마 변경 시 복잡. 대규모 인프라에서는 Green 준비 시간이 길어질 수 있음.
💡
비용 문제 해결: 클라우드 환경에서는 Blue-Green의 비용 문제가 크게 줄어든다. Green 환경을 배포할 때만 생성하고, 안정화 후 Blue를 삭제하면 두 환경이 동시에 존재하는 시간은 30분~1시간 정도. Auto Scaling과 Spot Instance를 활용하면 추가 비용을 최소화할 수 있다.
Canary 배포는 새 버전을 극소수의 사용자에게 먼저 노출하고, 문제가 없으면 점진적으로 전체에 확대하는 전략이다.
이름의 유래는 탄광의 카나리아새(canary in a coal mine)다. 과거 광부들은 독성 가스를 감지하기 위해 카나리아를 탄광에 먼저 보냈다. 카나리아가 무사하면 사람이 들어갔다. 마찬가지로, 소수의 트래픽으로 새 버전을 먼저 "탐지"하고, 안전하면 전체로 확대한다.
동작 원리
5%전체 트래픽의 5%를 v2로 라우팅. 에러율, 지연 시간, 비즈니스 메트릭을 실시간 모니터링.
25%5분간 이상 없음 확인 → 25%로 확대. 에러율이 기준치(예: 0.1%)를 넘으면 자동 롤백.
50%10분간 정상 → 50%로 확대. 응답 시간 p99가 기존 대비 20% 이상 느려지면 자동 롤백.
75%추가 10분 관찰 → 75%로 확대. 비즈니스 메트릭(전환율, 결제 성공률) 비교.
100%모든 지표 정상 → 100% 전환 완료. v1 인스턴스 종료.
자동 롤백의 힘
Canary 배포의 핵심 가치는 자동화된 의사결정이다. 사람이 모니터를 뚫어져라 쳐다보며 "이거 괜찮은 것 같은데..."라고 판단하는 것이 아니라, 미리 정의한 메트릭 기준에 따라 시스템이 자동으로 진행/롤백을 결정한다.
Canary 자동 판단 기준 예시
hljs language-yaml
canary:steps:-setWeight:5-pause: { duration:5m }
-analysis:metrics:-name:error-ratethreshold:0.1# 에러율 0.1% 초과 시 롤백-name:latency-p99threshold:500# p99 레이턴시 500ms 초과 시 롤백-name:success-ratethreshold:99.9# 성공률 99.9% 미만 시 롤백-setWeight:25-pause: { duration:10m }
-analysis:...-setWeight:50-pause: { duration:10m }
-setWeight:100
장단점
Canary 배포 특성
장점리스크 최소화 — 문제가 생겨도 5%만 영향. 실제 트래픽으로 검증. 자동 롤백 가능. 점진적 확대로 심리적 안정.
단점모니터링 인프라 필수. 전체 배포까지 시간이 오래 걸림. 트래픽 분할 로직 구현 필요. 통계적으로 유의미한 결과를 얻으려면 충분한 트래픽 필요.
5. A/B 테스트 vs Canary: 비슷해 보이지만 목적이 다르다
A/B 테스트와 Canary 배포는 둘 다 "일부 사용자에게 다른 버전을 보여준다"는 점에서 비슷해 보인다. 하지만 목적이 완전히 다르다.
구분
Canary 배포
A/B 테스트
목적
안전한 릴리즈
비즈니스 실험
핵심 질문
"이 버전이 안정적인가?"
"어떤 버전이 전환율이 높은가?"
측정 메트릭
에러율, 레이턴시, CPU 사용률
클릭률, 전환율, 매출
트래픽 비율
5% → 점진적 확대
50:50 (통계적 유의성 확보)
사용자 고정
불필요 (랜덤 라우팅)
필수 (같은 사용자 = 같은 버전)
종료 조건
기술 메트릭 정상 → 100% 전환
통계적 유의성 확보 → 우승 버전 선택
담당 팀
엔지니어링/DevOps
프로덕트/마케팅/데이터
Canary는 "이 코드가 프로덕션에서 안전한가?"를 확인하고, A/B 테스트는 "어떤 디자인/기능이 비즈니스에 더 유리한가?"를 확인한다.
실무에서는 이 둘을 결합하기도 한다. 새 기능을 Canary로 안전하게 배포한 후, Feature Flag으로 A/B 테스트를 실행하는 식이다. 이 때 Feature Flag이 핵심 역할을 한다.
6. Feature Flag: 코드는 배포하되, 기능은 아직 숨기기
개념
Feature Flag(기능 플래그, Feature Toggle이라고도 한다)은 코드를 배포하는 것과 기능을 활성화하는 것을 분리하는 기법이다.
쉽게 말하면: 가게에 새 메뉴판을 설치하되, 종이로 가려 놓는 것이다. 메뉴판(코드)은 이미 배포됐지만, 손님(사용자)은 볼 수 없다. 준비가 되면 종이(플래그)만 벗기면 된다.
Feature Flag 기본 패턴
hljs language-python
# 기능 플래그 확인if feature_flags.is_enabled("new-checkout-flow", user_id=user.id):
# 새로운 결제 플로우return new_checkout_handler(request)
else:
# 기존 결제 플로우return legacy_checkout_handler(request)
Feature Flag의 종류
Feature Flag 유형
릴리즈 플래그Release Toggle미완성 기능을 숨긴 채 배포. 준비되면 활성화. 단기 사용 후 제거.
실험 플래그Experiment ToggleA/B 테스트용. 사용자 그룹별로 다른 기능 노출. 실험 종료 후 제거.
운영 플래그Ops Toggle부하가 높을 때 특정 기능 비활성화(graceful degradation). 장기 유지.
권한 플래그Permission Toggle프리미엄 사용자에게만 기능 노출. 비즈니스 로직의 일부. 영구 유지.
Feature Flag + 배포 전략 = 최강 조합
Feature Flag은 단독으로도 유용하지만, 배포 전략과 결합하면 강력해진다.
코드 배포 (Canary)
→
플래그 OFF 상태
→
안전 확인 후 플래그 ON
이 조합의 장점:
배포와 릴리즈의 분리: 코드가 프로덕션에 있어도, 기능은 아직 사용자에게 보이지 않는다.
즉시 비활성화: 문제 발생 시 플래그만 끄면 된다. 재배포 불필요.
점진적 출시: 1% → 5% → 20% → 100% 식으로 기능을 점진적으로 공개할 수 있다.
시간 지정 릴리즈: "화요일 오전 10시에 새 기능 공개" — 마케팅 타이밍에 맞출 수 있다.
💡
Feature Flag 관리 주의: Feature Flag은 강력하지만, 관리하지 않으면 기술 부채가 된다. 한 코드베이스에 수백 개의 플래그가 쌓이면, if-else 분기가 폭발하고 테스트 조합이 기하급수적으로 늘어난다. 사용이 끝난 플래그는 반드시 제거하는 프로세스를 만들어야 한다. LaunchDarkly, Unleash 같은 전문 도구를 사용하면 플래그 라이프사이클 관리가 편해진다.
7. 전략 비교: Rolling vs Blue-Green vs Canary
여기까지 세 가지 핵심 배포 전략을 살펴봤다. 이제 한눈에 비교해 보자.
항목
Rolling
Blue-Green
Canary
다운타임
없음
없음
없음
배포 속도
느림 (순차 교체)
빠름 (순간 전환)
느림 (단계적 확대)
롤백 속도
느림 (역순 교체)
즉시 (라우팅 전환)
빠름 (트래픽 비율 복원)
리스크
중간 (점진적이지만 전체 대상)
낮음 (전환 전 충분한 테스트)
최소 (소수 트래픽만 노출)
인프라 비용
최소 (추가 서버 불필요)
높음 (2배 환경)
중간 (소수 추가 인스턴스)
구현 복잡도
낮음
중간
높음 (메트릭 + 자동화)
v1/v2 공존
있음 (배포 중)
없음 (순간 전환)
있음 (단계 진행 중)
실제 트래픽 검증
제한적
불가 (전환 전 내부 테스트만)
가능 (핵심 장점)
대표 사용처
ECS 기본, K8s 기본
AWS Elastic Beanstalk, 금융
Netflix, Google, 대형 SaaS
하나만 선택해야 하는 것은 아니다. 실무에서는 이 전략들을 조합한다. 예를 들어:
Blue-Green + Canary: Green 환경에 배포 후, 전체 전환 대신 Canary 방식으로 트래픽을 점진적으로 이동
Rolling + Feature Flag: Rolling으로 코드를 배포하되, 새 기능은 Flag으로 제어
Canary + 자동 롤백 + Feature Flag: 가장 정교한 조합. Netflix가 이 방식을 사용
8. AWS에서 구현하기
이론을 알았으니, 실제로 AWS에서 어떻게 구현하는지 살펴보자. AWS는 각 배포 전략을 위한 도구를 이미 제공하고 있다.
8-1. ECS Rolling Update (기본 내장)
ECS(Elastic Container Service)는 Rolling 배포를 기본 배포 방식으로 제공한다. 별도 설정 없이 바로 사용할 수 있다.
CodeDeploy배포 전략 관리. Canary/Linear/AllAtOnce. 자동 롤백.
ALB가중치 라우팅. Blue/Green 타겟 그룹 간 트래픽 분배.
ECS Blue (v1)현재 라이브 태스크. 트래픽 점진적 감소.
ECS Green (v2)새 버전 태스크. 트래픽 점진적 증가.
CloudWatch메트릭 모니터링. 알람 → 자동 롤백 트리거.
9. 실전 사례: Netflix와 Amazon
Netflix: Canary 배포의 교과서
Netflix는 Canary 배포를 가장 정교하게 운영하는 기업 중 하나다. Spinnaker라는 오픈소스 배포 플랫폼을 직접 만들어 공개했다.
Netflix의 Canary 분석 시스템 Kayenta는 단순히 "에러율이 높은가?"만 보지 않는다. 통계적 가설 검정(statistical hypothesis testing)을 사용한다.
1
문제: 감각적 판단의 한계
배포 담당자가 "에러가 좀 늘었는데, 이게 새 버전 때문인지 자연적인 변동인지 모르겠다"라고 판단을 미루면 장애가 확대된다.
2
해결: 자동 통계 분석 (Kayenta)
Canary(v2)와 Baseline(v1)의 메트릭을 동일 시간대에 수집하고, Mann-Whitney U 검정으로 차이가 통계적으로 유의미한지 자동 판단한다.
3
결과: 인간 개입 최소화
Kayenta가 canary score를 0~100으로 산출한다. 임계값(보통 75점) 미만이면 자동 롤백. 이 시스템 덕분에 Netflix는 하루 수천 번 배포하면서도 사용자 영향을 최소화한다.
Netflix Canary 배포의 핵심 원칙:
항상 Baseline을 함께 띄운다: v1 트래픽의 일부를 "새로 띄운 v1 인스턴스(Baseline)"로도 보낸다. Canary(v2) vs Baseline(v1)을 동일 조건에서 비교해야 정확하다.
충분한 데이터를 수집한다: 최소 30분 이상 관찰. 짧은 관찰은 노이즈에 속을 수 있다.
여러 메트릭을 종합 판단한다: CPU, 메모리, 에러율, 레이턴시 p50/p99, JVM GC 시간 등 수십 개의 메트릭을 동시에 비교한다.
Amazon: One-Box 배포
Amazon은 One-Box 배포라는 독자적인 Canary 변형을 사용한다. 전체 리전의 서버 중 딱 한 대(one box)에만 새 버전을 배포하고, 그 한 대의 메트릭을 나머지 서버들과 비교한다.
One-Box한 리전의 서버 수천 대 중 1대에만 v2 배포. 최소 1시간 모니터링. 이 단계에서 대부분의 문제가 발견된다.
Regional한 리전 전체에 Rolling 배포. 다른 리전은 아직 v1. 리전 간 비교 모니터링.
Global모든 리전에 순차적으로 배포. 전 세계 완료까지 수 시간~수일 소요.
Amazon이 이 방식을 사용하는 이유: 글로벌 규모에서의 안전. 전 세계 수십 개 리전에 동시에 배포하면, 문제 발생 시 영향 범위가 너무 크다. One-Box → Regional → Global의 3단계 확산으로, 문제를 가장 이른 시점에 가장 작은 범위에서 잡는다.
💡
Amazon의 "blast radius" 철학: Amazon 내부에서는 배포 문제의 영향 범위를 "폭발 반경(blast radius)"이라 부른다. 모든 배포 설계의 목표는 이 폭발 반경을 최소화하는 것이다. One-Box 배포는 폭발 반경을 딱 1대로 제한한다는 점에서 가장 안전한 첫 단계다.
10. 데이터베이스 마이그레이션: 배포 전략의 숨은 난제
배포 전략을 설명할 때 흔히 빠지는 것이 있다. 데이터베이스다.
애플리케이션 서버는 여러 대를 띄울 수 있고, 트래픽을 나눌 수 있지만, 데이터베이스는 보통 하나다. v1과 v2가 공존하는 Rolling/Canary 배포 중에 DB 스키마가 바뀌면 어떻게 될까?
DB를 v2에 맞게 바꾸면 v1이 깨지고, v1에 맞게 놔두면 v2가 깨진다. Blue-Green 배포라면 순간 전환이므로 이 문제가 상대적으로 적지만, Rolling과 Canary에서는 심각하다.
올바른 접근: Expand-Contract 패턴
DB 스키마 변경은 3단계로 나누어 진행한다.
Expand (확장)새 컬럼 username을 추가한다. 기존 user_name은 그대로 유지. v1은 user_name을 읽고, v2는 username을 읽되 user_name도 동기화. 둘 다 정상 동작.
Migrate (마이그레이션)모든 서버가 v2로 전환 완료. user_name → username으로 데이터 복사 스크립트 실행. 모든 코드가 username을 사용하는지 확인.
Contract (정리)user_name 컬럼 삭제. 이 시점에서 모든 서버는 v2이므로 안전.
이 패턴의 핵심: DB 변경은 코드 배포보다 최소 한 단계 앞서야 한다. 코드가 v1 → v2로 바뀌기 전에, DB는 이미 v1과 v2를 모두 지원하는 상태여야 한다.
11. 선택 가이드: 우리 팀에 맞는 전략은?
"어떤 전략이 가장 좋은가?"라는 질문에 정답은 없다. 팀의 상황에 따라 다르다.
의사결정 프레임워크
시작: 무중단 배포 필요?
NO → Recreate 배포로 충분
|
YES ↓
모니터링 인프라가 갖춰져 있는가?
NO → Rolling 배포 (가장 단순)
|
YES ↓
빠른 롤백이 최우선인가?
YES → Blue-Green 배포
|
NO ↓
실제 트래픽으로 검증이 필요한가?
YES → Canary 배포
|
아직 결정 못함 → Blue-Green으로 시작
팀 규모와 성숙도별 추천
팀 상황
추천 전략
이유
1~3명, 초기 스타트업
Rolling (ECS 기본)
추가 설정 없이 바로 사용. 비용 최소. ECS 서비스 생성만 하면 끝.
5~15명, 성장기
Blue-Green (CodeDeploy)
즉시 롤백의 안정감. CodeDeploy가 자동 관리. 모니터링 인프라 구축 시작 시점.
15~50명, 확장기
Canary + Feature Flag
다수 팀이 독립 배포. 실제 트래픽 검증 필수. 자동 롤백으로 사고 예방.
50명+, 대규모
Canary + Feature Flag + A/B
프로덕트/엔지니어링 협업. 실험 문화. Spinnaker/Argo Rollouts 도입.
산업별 고려사항
핀테크/금융: Blue-Green 선호. 즉시 롤백이 규제 요건인 경우가 많다. Canary의 "5% 사용자가 버그를 경험"이 허용되지 않을 수 있다.
이커머스: Canary + Feature Flag. 매출에 직접 영향을 미치므로, 실제 트래픽으로 전환율을 검증해야 한다.
미디어/스트리밍: Canary가 필수. 비디오 재생 품질, 버퍼링 비율 같은 사용자 경험 메트릭을 실시간 비교해야 한다.
내부 도구/B2B SaaS: Rolling으로 시작해도 충분. 사용자가 상대적으로 적고, 문제 발생 시 직접 소통이 가능하다.
12. 실전 체크리스트: 무중단 배포를 시작하기 전에
어떤 전략을 선택하든, 다음 사항을 먼저 갖춰야 한다.
필수 인프라
무중단 배포 필수 인프라
헬스 체크새 인스턴스가 정상인지 확인하는 엔드포인트. /health가 200을 반환해야 트래픽을 받는다.
로드밸런서트래픽 분배와 라우팅 전환의 핵심. ALB, NLB, 또는 Envoy.
모니터링/알림배포 중 에러율, 레이턴시를 실시간 감지. CloudWatch, Datadog, Grafana.
CI/CD 파이프라인코드 변경 → 빌드 → 테스트 → 배포를 자동화. 수동 배포는 반드시 실수를 만든다.
코드 레벨 준비사항
Graceful Shutdown: 서버가 종료 신호(SIGTERM)를 받으면, 처리 중인 요청을 완료한 후 종료해야 한다. 갑자기 끊으면 사용자가 에러를 경험한다.
Node.js Graceful Shutdown 예시
hljs language-javascript
process.on('SIGTERM', async () => {
console.log('SIGTERM received. Graceful shutdown...');
// 새 요청 수신 중단
server.close();
// 처리 중인 요청 완료 대기 (최대 30초)awaitnewPromise(resolve =>setTimeout(resolve, 30000));
// DB 연결 종료await db.disconnect();
process.exit(0);
});
Backward Compatible API: v1과 v2가 공존할 수 있도록, API 변경은 항상 하위 호환성을 유지한다. 필드를 삭제하지 말고, 새 필드를 추가하라.
DB 마이그레이션 분리: 스키마 변경은 코드 배포와 별도로 실행한다. Expand-Contract 패턴을 사용한다.
헬스 체크 엔드포인트: 단순 200 OK가 아니라, DB 연결, 캐시 상태, 의존 서비스 연결까지 확인하는 심층 헬스 체크를 구현한다.