들어가며: 오전 10시, 당신의 하루
오전 10시. 당신은 이미 전쟁터 한복판에 있다.
고객사 보고서를 쓰다가 팀장이 "이번 분기 예산 스프레드시트 업데이트했어?"라고 묻는다. 슬랙에는 마케팅팀이 발표자료 검토를 요청한 알림이, 이메일에는 거래처가 보낸 계약서 수정본이 쌓여 있다. 보고서에 넣을 데이터는 엑셀에서 뽑아야 하고, 그 엑셀은 동료가 아직 보내지 않았다.
하나의 일을 하는 게 아니다. 수십 개의 일이 동시에 당신을 당긴다.
이것이 지식 노동(knowledge work)의 현실이다. 그리고 2026년, AI 에이전트에게 이 현실을 가르치려는 시도가 시작됐다.
AI 에이전트, 현실의 사무실은 알고 있나?
벤치마크의 환상
2024년부터 AI 에이전트 벤치마크는 폭발적으로 늘었다. OSWorld, WebArena, GAIA, τ²-bench 등 다양한 벤치마크가 등장하며 "AI가 컴퓨터를 얼마나 잘 쓰는가"를 측정했다.
하지만 한 가지 치명적인 공통점이 있다. 모든 벤치마크가 "하나의 작업"만 평가한다는 것이다.
"이 엑셀에서 매출 합계를 구하라", "이 웹사이트에서 정보를 찾아라", "이 이메일을 작성하라" — 하나씩, 깨끗하게, 독립적으로.
!
문제
기존 벤치마크는 한 번에 한 가지 작업만 평가한다. 하지만 현실의 지식 노동자는 45개 이상의 작업을 동시에 처리한다.
→
근본 원인
단일 작업 벤치마크에서 높은 점수를 받은 AI 에이전트도, 작업이 동시에 쌓이면 완료율이 절반 이하로 급락한다.
∴
시사점
AI 에이전트를 현실 업무에 투입하려면, "멀티태스킹"이라는 전혀 다른 차원의 문제를 해결해야 한다.
현실의 사무실에서는 아무도 "다른 일은 전부 멈추고, 이것만 해"라고 말해주지 않는다. 보고서를 쓰다가 급한 이메일에 응답하고, 엑셀을 수정하다가 파워포인트를 검토하고, 다시 보고서로 돌아온다. 이것이 진짜 일이다.
역사 한 스푼: 에이전트는 어떻게 여기까지 왔나
CORPGEN을 이해하려면, AI 에이전트가 어떤 진화 과정을 거쳐왔는지 잠깐 되짚어볼 필요가 있다. 왜냐하면 CORPGEN이 해결하려는 문제 — "AI가 여러 일을 동시에 해야 한다" — 는 사실 아주 오래된 꿈의 연장선이기 때문이다.
1986: 민스키의 "마음의 사회"
마빈 민스키는 The Society of Mind에서 지능이란 수많은 단순한 에이전트의 협업에서 창발한다고 주장했다. 각 에이전트는 단순하지만, 그들의 "사회"가 복잡한 행동을 만들어낸다. 2026년의 멀티 에이전트 시스템은 이 아이디어를 놀랍도록 충실하게 구현하고 있다.
2022: ReAct — 생각하고 행동하라
Princeton과 Google의 연구진이 발표한 ReAct(Reason + Act) 프레임워크는 AI 에이전트의 핵심 작동 원리를 정립했다. "생각(Thought) → 행동(Action) → 관찰(Observation)"을 반복하는 루프. 이것이 오늘날 거의 모든 AI 에이전트의 뼈대가 되었다.
THOUGHT고객 보고서를 마무리하려면 Q4 매출 데이터가 필요하다
ACTIONExcel 열기 → Q4_매출.xlsx에서 합계 추출
OBSERVEQ4 매출 합계: 12.4억 원. 보고서에 삽입 가능
THOUGHT데이터를 확보했으니 보고서의 3번째 섹션을 작성하자
ACTIONWord 열기 → "실적 분석" 섹션에 매출 데이터 삽입
OBSERVE섹션 완료. 다음은 차트 삽입 필요
하나의 작업에서 이 루프는 아름답게 작동한다. 문제는 이 루프가 "하나의 작업"만 알고 있다는 것이다.
2023–2024: 에이전트 프레임워크 전쟁
LangChain, CrewAI, AutoGPT, MetaGPT — 멀티 에이전트 프레임워크들이 쏟아져 나왔다. 하지만 대부분은 "미리 정해진 역할"에 따라 협업하는 구조였다. "프로그래머 에이전트가 코드를 쓰고, 테스터 에이전트가 테스트한다"는 식의 고정된 파이프라인. 현실의 사무실처럼 "그때그때 상황에 따라 우선순위를 바꾸면서 여러 일을 동시에 처리하는" 것과는 거리가 멀었다.
2024: OSWorld — 진짜 컴퓨터를 쓸 수 있나?
NeurIPS 2024에서 발표된 OSWorld는 AI 에이전트가 실제 운영체제에서 마우스와 키보드로 작업을 수행하는 벤치마크를 제시했다. 인간의 성공률 72%, 최고 AI의 성공률 12%. 여전히 격차가 컸지만, 중요한 건 "AI가 실제 컴퓨터 앞에 앉았다"는 사실이었다.
2025: UFO2 — Windows의 AI 자동화
Microsoft의 UFO2는 Windows에서 GUI를 자동으로 조작하는 에이전트를 선보였다. 접근성 API와 시각적 인식을 결합해 Word, Excel, PowerPoint 등 실제 오피스 앱을 조작할 수 있었다. 이것이 CORPGEN의 "손과 발"이 된다.
2026년 2월: CORPGEN의 등장
그리고 2026년 2월, Microsoft Research가 핵심 질문을 던졌다.
"AI 에이전트가 컴퓨터 하나를 쓸 수 있다는 건 증명했다. 그런데 진짜 직원처럼 하루 종일 수십 개의 일을 동시에 처리할 수 있을까?"
답은 CORPGEN이었다.
MHTE: "진짜 일"을 시뮬레이션하다
Multi-Horizon Task Environment란 무엇인가
CORPGEN 논문의 가장 중요한 기여 중 하나는 MHTE(Multi-Horizon Task Environment)라는 새로운 평가 개념을 정립한 것이다. 기존 벤치마크와 완전히 다른 차원의 평가 환경이다.
| 비교 항목 | 기존 벤치마크 (Long-Horizon) | MHTE |
|---|
| 동시 작업 수 | 1개 | 45개 이상 |
| 작업당 단계 | 10~20 | 10~30+ |
| 총 단계 수 | 10~20 | 500~1,500+ |
| 동시성 | 없음 | 높음 |
| 작업 간 의존성 | N/A | DAG / 순환 구조 |
| 우선순위 재조정 | 드묾 | 빈번 |
| 컨텍스트 성장 | O(1) | O(N) |
| 기억 간섭 | 없음 | 높음 |
| 기저선 성능 | 안정적 | 재앙적 하락 |
쉽게 말하면 이렇다. 기존 벤치마크가 "시험 문제 하나 풀기"라면, MHTE는 "시험 50개를 동시에 풀면서, 문제들이 서로 영향을 주고, 중간에 선생님이 순서를 바꾸는" 상황이다.
구체적인 MHTE 시나리오
CORPGEN의 MHTE는 OSWorld Office를 기반으로 구성된다. 총 46개 작업이 동시에 주어진다:
- Excel 11개: 예산 계산, 매출 분석, 데이터 정리 등
- Word 9개: 보고서 작성, 계약서 수정, 메모 정리 등
- PowerPoint 7개: 발표자료 제작, 슬라이드 업데이트 등
- 멀티앱 19개: 여러 앱을 오가며 수행하는 복합 작업
각 작업은 10~30개의 의존적 단계로 이루어져 있고, 작업들 사이에도 의존 관계가 얽혀 있다. 예를 들어:
Task A: 보고서 작성
↓ 의존
Task B: 데이터 분석 (Excel)
↓ 의존
Task C: 동료에게 데이터 요청
↓ 의존 (순환!)
Task A: 요구사항 확인을 위해 보고서 초안 필요
보고서를 쓰려면 데이터가 필요하고, 데이터를 받으려면 요청을 보내야 하는데, 요청 내용을 정하려면 보고서 초안이 필요하다. 현실의 업무란 이렇게 꼬여 있다.
붕괴의 4가지 패턴: AI가 멀티태스킹에 실패하는 이유
CORPGEN 연구팀은 기존 AI 에이전트(Computer Using Agents, CUA)를 MHTE에 투입했다. 결과는 처참했다. 작업이 늘어날수록 성능이 체계적으로 무너졌다. 그 원인을 4가지로 분석했다.
1. 컨텍스트 윈도우 포화 (Context Saturation)
하나의 작업을 할 때, 에이전트가 기억해야 할 정보는 그 작업에 관한 것뿐이다 — O(1). 하지만 46개 작업을 동시에 처리하면? 모든 작업의 상태를 동시에 기억해야 한다 — O(N). 컨텍스트 윈도우가 순식간에 가득 찬다.
2. 교차 작업 기억 간섭 (Cross-Task Memory Interference)
"Q4 스프레드시트를 업데이트하라"는 지시를 받았다. 그런데 영업 보고서의 Q4 스프레드시트인가, 엔지니어링 보고서의 Q4 스프레드시트인가? 여러 작업이 하나의 컨텍스트를 공유하면, 한 작업의 정보가 다른 작업의 추론을 오염시킨다.
3. 의존성 그래프 복잡도 (Dependency Complexity)
단일 작업의 의존성은 선형이거나 트리 구조다. MHTE에서는 방향성 비순환 그래프(DAG), 심지어 순환 의존성까지 등장한다. 작업 A가 B에, B가 C에, C가 다시 A에 의존하는 상황. 에이전트는 이 복잡한 그래프를 탐색하며 "지금 무엇을 할 수 있는지"를 매 순간 판단해야 한다.
4. 재우선순위화 부담 (Reprioritization Overhead)
단일 작업에서는 "다음에 뭘 할까"가 명확하다 — 현재 작업의 다음 단계. 하지만 MHTE에서는 매 행동 사이클마다 46개 작업 전체를 다시 평가해야 한다. "이 작업이 막혔으니 저 작업으로 넘어가야 하나? 아, 그 작업은 아직 선행 조건이 완료되지 않았네. 그럼 이쪽을 먼저..." — O(N)의 의사결정 복잡도가 매 사이클 반복된다.
실제 성능 하락 데이터
작업 부하 증가에 따른 AI 에이전트 완료율 변화
OSWorld Office 기준 · 3개 CUA 백엔드 평균
12개 작업(25% 부하)에서 46개 작업(100% 부하)으로 늘리면, 모든 에이전트의 완료율이 절반 가까이 떨어진다. 이건 특정 에이전트의 문제가 아니다 — 3개의 서로 다른 아키텍처가 모두 같은 패턴으로 무너졌다. 구조적인 문제라는 뜻이다.
CORPGEN: 디지털 직원의 탄생
이제 본론이다. CORPGEN(Corporate Environment Generation)은 이 4가지 문제를 정면으로 해결하는 프레임워크다. 핵심 아이디어는 간단하면서도 강력하다.
AI 에이전트를 "도구"가 아닌 "직원"으로 설계하라.
CORPGEN의 "디지털 직원(Digital Employee)"은 진짜 직원처럼 작동한다:
- 영속적 정체성: 이름, 역할, 전문성이 있고 세션이 바뀌어도 유지된다
- 근무 스케줄: 오전 8시~오후 6시(±10분 변동) 동안 일한다
- 하루 루틴: 출근 시 계획 수립, 업무 수행, 퇴근 시 회고와 기록
디지털 직원의 하루
08:00 출근이전 세션의 기억 로드 → 월간 목표 확인 → 오늘의 일일 계획 수립 (6~12개 태스크, 우선순위 배정)
실행 사이클컨텍스트 검색 → 다음 작업 선택 → ReAct 루프 실행 → 결과 저장. 50개 이상의 작업을 인터리빙하며 반복
실행 사이클작업 완료/차단 시 → 계획 업데이트 → 우선순위 재조정 → 다음 사이클로. 최소 5분 간격
재시도 정책작업 실패 시 최대 3회(각 30회 반복 한도) 재시도. 불가능한 작업은 스킵하고 다음으로
18:00 퇴근하루 회고 생성 → 경험을 장기 기억으로 통합 → 다음 세션을 위한 인사이트 저장
이 구조가 단순해 보일 수 있지만, 핵심은 "하나의 거대한 루프"가 아니라 "작은 실행 사이클의 반복"이라는 점이다. 각 사이클에서 에이전트는 새로 깨어난 것처럼 기억을 검색하고, 상황을 판단하고, 가장 적절한 작업을 선택한다. 이것이 컨텍스트 포화를 방지하는 첫 번째 열쇠다.
4가지 핵심 메커니즘: 해부
CORPGEN이 멀티태스킹의 4가지 실패 패턴을 해결하는 방법을 하나씩 살펴보자.
메커니즘 1: 계층적 계획 (Hierarchical Planning)

인간이 일하는 방식을 생각해 보자. "이번 달 안에 신제품 보고서 마무리"라는 전략적 목표가 있고, "오늘은 시장 조사와 경쟁사 분석을 끝내자"라는 전술적 계획이 있으며, "지금 당장은 이 엑셀 데이터부터 정리하자"라는 즉시 행동이 있다.
CORPGEN의 디지털 직원도 정확히 이 3계층으로 계획한다:
CORPGEN 계층적 계획 구조
전략적 목표 (월간)
"GPT-5 예비 조사 보고서 — 2주차: 조사, 3주차: 초안, 월말: 발표"
전술적 계획 (일간)
6~12개 태스크: Word 보고서, Excel 분석, Edge 리서치...
운영적 행동 (사이클당)
현재 상태 + 도구 + 기억 → 지금 이 순간 최적의 행동 선택
왜 이게 중요한가? 계획 없이 46개 작업을 마주하면, 에이전트는 매 순간 "46개 중 뭘 할까?"를 처음부터 고민해야 한다. 계층적 계획이 있으면, "오늘 할 일 6개" 중에서 "지금 할 수 있는 것 1개"만 고르면 된다. O(N)의 결정 복잡도가 O(1)에 가깝게 줄어든다.
작업 완료나 차단이 발생하면, 변경 사항이 계층 구조를 타고 전파된다. 일일 계획이 수정되고, 필요하면 월간 목표까지 조정된다.
메커니즘 2: 격리된 서브에이전트 (Sub-Agents as Tools)
두 번째 문제인 "교차 작업 기억 간섭"을 해결하는 핵심 장치다.
에이전트가 웹 리서치를 해야 한다고 하자. 브라우저를 열고 10개 페이지를 돌아다니며 정보를 모으는 동안, 그 모든 중간 과정이 메인 컨텍스트에 쌓이면 어떻게 될까? 엑셀 작업에 대한 기억 위에 웹 검색 결과가 덮이고, 다시 Word 작업으로 돌아가면 혼란이 시작된다.
CORPGEN의 해법: 서브에이전트를 "도구"로 감싸서 격리된 컨텍스트에서 실행한다.
서브에이전트 격리 아키텍처
호스트 에이전트 (메인 컨텍스트)
계획 수립, 작업 선택, 결과 통합
🔍 리서치 에이전트
격리된 컨텍스트
쿼리 수신 → 웹 탐색 → 구조화된 보고서 반환
🖥️ UFO2 (CUA)
격리된 컨텍스트
GUI 명령 수신 → 앱 조작 → 결과 반환
리서치 에이전트는 shallow(1단계) / medium(2단계) / deep(3단계) 깊이로 조사를 수행하고, 구조화된 보고서만 호스트에게 돌려보낸다. 중간 과정의 잡음은 호스트 컨텍스트에 전혀 전달되지 않는다.
이것은 단순한 기술적 트릭이 아니다. "인지 도구(Cognitive Tools)"와의 차이를 주목하자:
- 인지 도구: 에이전트가 어떻게 생각해야 하는지를 구조화한다 (계획, 추적, 회고)
- 서브에이전트: 복잡한 작업을 독립적으로 수행하고 결과만 돌려준다
마치 사무실에서 "이 조사 좀 해줘"라고 동료에게 부탁하는 것과, 스스로 체크리스트를 만들어 관리하는 것의 차이다. 둘 다 필요하다.
메커니즘 3: 3계층 기억 아키텍처 (Tiered Memory)
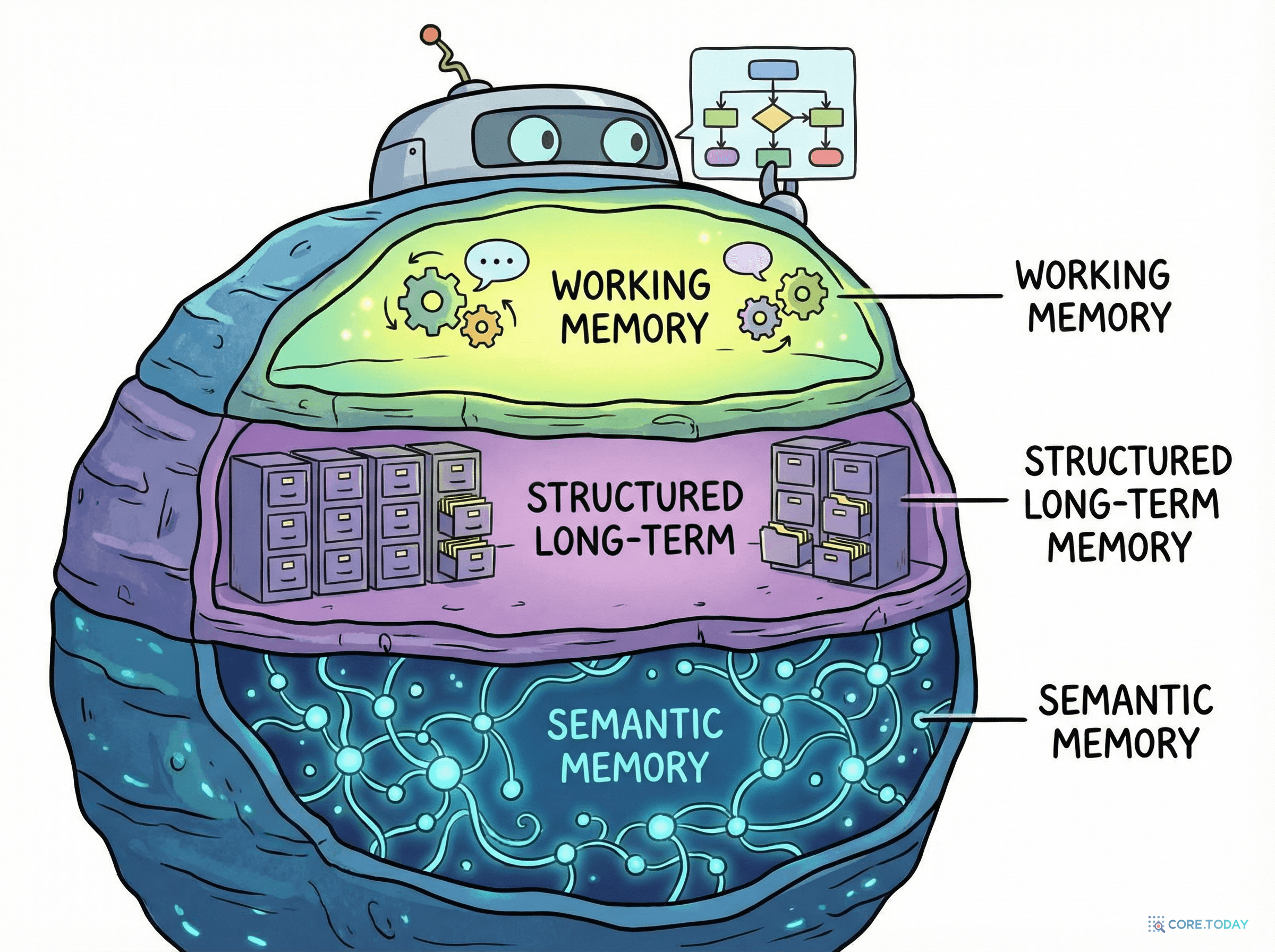
인간의 기억 시스템을 모방한 CORPGEN의 핵심 설계다.
CORPGEN 3계층 기억 아키텍처
💡 작업 기억 (Working Memory)
지금 이 사이클에서 필요한 즉시 정보. 매 사이클 리셋
📋 구조화된 장기 기억 (Structured LTM)
계획, 행동 요약, 회고 등 타입이 지정된 아티팩트
🧠 의미적 기억 (Semantic Memory)
Mem0 통합
과거 맥락에 대한 유사성 기반 검색. 비구조화된 경험 전체를 커버
매 실행 사이클이 시작될 때, 기억 검색은 고정된 우선순위를 따른다:
- 최근 접근한 항목을 우선
- 중요 표시된 기록(작업 상태 변경, 계획 업데이트, 실패 등)을 우선
- 의미적으로 관련된 과거 컨텍스트
상위 k개의 항목만 작업 기억에 주입되어, 핵심 정보는 접근 가능하면서도 컨텍스트는 제한된 상태를 유지한다.
비유하자면, 인간이 일할 때 "모든 기억을 동시에 떠올리지 않는다". 필요한 것만 꺼내 쓴다. CORPGEN의 기억 시스템도 마찬가지다.
메커니즘 4: 적응적 요약 (Adaptive Summarization)
아무리 기억을 계층화해도, 수시간 동안 실행되면 컨텍스트는 결국 커진다. CORPGEN은 규칙 기반 적응적 요약으로 이를 제어한다.
컨텍스트 내용을 두 가지로 분류한다:
🔒 Critical — 절대 압축하지 않음
도구 호출 결과 · 작업 상태 변경 · 계획 업데이트 · 오류/복구 신호
📝 Routine — 압축 대상
중간 관찰 · 일시적 추론 과정 · 반복적 UI 상태 확인
컨텍스트가 4,000토큰을 넘으면, Routine 내용이 결정사항, 차단 요인, 현재 앱 상태만 남기는 짧은 구조적 요약으로 압축된다. 그래도 계속 커지면, 추가 압축이 적용되되 모든 작업 수준 상태는 보존된다.
경험 학습: CORPGEN의 비밀 무기

4가지 메커니즘 중 가장 놀라운 성능 향상을 가져온 것은 사실 따로 있다. 경험 학습(Experiential Learning)이다.
어떻게 작동하는가
성공작업이 성공적으로 완료되면, 실행 과정을 최소화된 정규 궤적으로 증류한다 (컨텍스트, 앱 상태, 올바른 행동 시퀀스)
임베딩sentence-transformer 모델로 궤적을 벡터화한다
인덱싱앱별 FAISS 데이터베이스에 저장한다 (Excel 궤적은 Excel DB에, Word 궤적은 Word DB에)
재사용새로운 작업 실행 시, 같은 앱의 유사 궤적 top-k개를 few-shot 예시로 주입한다
이것이 왜 강력한가? 일반적인 AI 에이전트는 매번 처음부터 모든 것을 탐색해야 한다. "Excel에서 피벗 테이블을 만드는 법"을 한 번 성공적으로 수행했어도, 다음번에 같은 작업을 만나면 또 시행착오를 거친다.
하지만 CORPGEN의 디지털 직원은 과거의 성공 경험을 기억하고 재활용한다. 마치 숙련된 직원이 "아, 이거 저번에 했던 것과 비슷하네"라고 하는 것과 같다.
중요한 설계 선택: 피드백은 계층적 플래너가 아니라 실행 에이전트(UFO2)에 직접 라우팅된다. 논문에 따르면 이 방식이 플래너를 경유하는 것보다 더 효과적이다. "계획을 잘 세우는 법"보다 "실제 버튼을 잘 누르는 법"을 학습하는 게 더 실용적이라는 뜻이다.
협업의 창발: 여러 디지털 직원이 함께 일할 때

CORPGEN의 가장 흥미로운 부분은 멀티 에이전트 협업이다. 여러 디지털 직원이 같은 환경에서 일할 때, 그들은 어떻게 협력할까?
놀랍게도 답은 "우리가 하는 것과 똑같이"다.
- 이메일로 비동기 요청을 보내고
- Microsoft Teams로 메시지를 주고받고
- 공유 문서로 작업 결과를 전달한다
미리 정해진 조율 규칙은 없다. MetaGPT나 CrewAI처럼 "너는 프로그래머, 너는 테스터"라고 역할을 강제하지 않는다. 대신, 각 에이전트가 독립적으로 판단하고, 필요할 때 표준 커뮤니케이션 채널을 통해 협력한다.
시간이 지나면서 흥미로운 패턴이 창발한다:
- 일부 에이전트가 자연스럽게 리더 역할을 맡고
- 다른 에이전트들이 지원 기능을 수행하며
- 공유 문서가 연결 조직(connective tissue)으로 기능한다
이메일 전송이 실패하면? 에이전트는 자동으로 Teams로 우회하여 메시지를 전달한다. 현실의 직원이 "이메일 안 되나? 슬랙으로 보내야겠다"고 판단하는 것과 같다.
실험 결과: 숫자가 말하는 것
핵심 결과: 부하 저항성
46개 작업(100% 부하) 기준 완료율 비교
CORPGEN vs 기저선 · OSWorld Office
46개 작업을 동시에 처리할 때:
- 기저선(UFO2): 4.3%
- CORPGEN: 15.2%
- 향상 배율: 3.5배
15.2%가 낮아 보일 수 있다. 하지만 이 맥락을 기억하자 — 이건 6시간 동안 46개 작업, 500~1,500 단계를 실제 GUI로 처리하는 것이다. 인간도 같은 조건이면 100%를 달성하기 어렵다.
컴포넌트별 기여도 분석
어떤 메커니즘이 가장 큰 차이를 만드는가?
100% 부하 · 컴포넌트 순차 추가 실험
흥미로운 패턴이 보인다:
- 인지 모델을 추가하면 중간 정도의 개선 (4.3% → 8.7%)
- 인지 도구를 추가해도 추가 개선은 미미 (8.7% → 8.7%)
- 경험 학습을 추가하면 급격한 개선 (8.7% → 15.2%)
논문의 해석: 단기 실행에서는 인지 도구와 인지 모델의 효과가 상당 부분 겹친다. 진짜 차이를 만드는 것은 경험 학습이다. 과거의 성공을 기억하고 재활용하는 능력이 가장 큰 성능 향상을 가져온다.
이것은 인간의 업무 학습 곡선과도 일치한다. 신입 사원이 빠르게 성장하는 시점은 "계획을 잘 세울 때"가 아니라 "비슷한 일을 해본 경험이 쌓였을 때"다.
평가 방법론의 발견
CORPGEN 연구에서 나온 또 하나의 중요한 발견:
❌
스크린샷 기반 평가
실행 과정의 스크린샷과 행동 로그만으로 평가 → 인간 판단과의 일치율 ~40%
✓
아티팩트 기반 평가
실제 생성된 파일(Excel, Word 등)을 검사 → 인간 판단과의 일치율 ~90%
기존의 스크린샷 기반 평가는 에이전트의 실제 능력을 절반도 제대로 측정하지 못한다. "어떻게 했는지(과정)"보다 "무엇을 만들었는지(결과물)"를 보는 것이 훨씬 정확하다는 것이다. 이것은 향후 AI 에이전트 벤치마크 설계에 큰 영향을 줄 발견이다.
2026년 맥락에서 바라보기: 왜 지금 이것이 중요한가
AI 에이전트 시장의 현재
2026년 3월 현재, Gartner는 2026년 말까지 엔터프라이즈 애플리케이션의 40%가 AI 에이전트를 내장할 것으로 전망한다. 멀티 에이전트 시스템 문의는 2024년 대비 1,445% 급증했다. 하지만 Salesforce의 설문에 따르면 기업 AI 에이전트 담당자들이 꼽는 최대 장벽은 신뢰성(reliability)이다.
CORPGEN은 이 신뢰성 문제의 핵심을 짚었다. AI 에이전트가 데모에서는 잘 작동하지만 현실에서 무너지는 이유는, "현실의 업무는 멀티태스킹"이기 때문이다.
CORPGEN이 가리키는 방향
1
기억과 검색이 핵심 병목
모델 자체의 능력보다, 적절한 정보를 적절한 시점에 기억하고 검색하는 능력이 실무 성능을 결정한다. 더 큰 모델보다 더 좋은 기억 시스템이 필요하다.
2
아키텍처가 모델만큼 중요하다
CORPGEN은 특정 모델에 의존하지 않는 아키텍처 중립 프레임워크다. UFO2, OpenAI CUA, 계층적 CUA 등 어떤 백엔드를 넣어도 동일한 패턴의 개선이 나타났다. 시스템 설계의 힘이다.
3
경험이 계획을 이긴다
정교한 계획 시스템보다 과거 성공 경험의 재활용이 더 큰 성능 향상을 가져온다. 이것은 인간의 전문성 발달 경로와도 일치한다.
한계와 미래
CORPGEN은 연구 프레임워크이지 배포 시스템이 아니다. 저자들이 솔직하게 인정하는 한계들이 있다:
- GUI 기반 조작의 느림: 스크린샷 기반 상호작용은 API 접근보다 느리고 불안정하다. 향후 API와 시각적 이해를 결합하는 하이브리드 접근이 필요하다
- 상태 관리의 어려움: CUA는 UI 요소가 준비되기 전에 행동하거나, 비활성화된 컨트롤을 잘못 해석하는 문제가 있다
- 비용과 확장성: 영속적 디지털 직원을 유지하는 데 상당한 계산 비용이 든다
- 실제 기업 데이터 부재: 합성 환경에서의 검증이며, 실제 기업 행동 데이터는 아직 없다
이런 한계에도 CORPGEN의 핵심 기여는 명확하다. MHTE라는 새로운 문제 정의와 그 문제에 대한 체계적인 해법을 제시했다는 것. 이것은 단일 작업 벤치마크에서 100% 달성을 향해 달리던 업계에게 "방향이 잘못됐다"고 말하는 것과 같다.
마치며: 진짜 직원처럼 일한다는 것
이 글의 처음으로 돌아가 보자. 오전 10시, 수십 개의 작업을 저글링하는 당신.
당신이 이 모든 일을 (어느 정도) 해낼 수 있는 이유는 뭘까?
- 우선순위를 정하는 계획 능력 — 무엇을 먼저 하고 무엇을 미룰지 판단한다
- 일을 분리하는 인지 능력 — 보고서와 스프레드시트의 맥락을 섞지 않는다
- 필요한 것만 기억하는 능력 — 지금 당장 관련 있는 정보만 꺼내 쓴다
- 경험에서 배우는 능력 — "이거 저번에 했던 것과 비슷하네"라고 판단한다
CORPGEN의 디지털 직원은 이 네 가지를 그대로 모방한다. 계층적 계획, 서브에이전트 격리, 3계층 기억, 경험 학습. 인간의 업무 방식을 기술적으로 구현한 것이다.
15.2%의 완료율은 아직 인간에 비해 한참 부족하다. 하지만 이것은 시작이다. CORPGEN이 보여준 것은 AI 에이전트가 "하나의 작업을 잘 하는 도구"에서 "여러 작업을 동시에 처리하는 동료"로 진화하는 첫 번째 발걸음이다.
그리고 3.5배의 성능 향상이 모델이 아니라 아키텍처에서 나왔다는 사실은, 이 방향에 아직 거대한 개선 여지가 남아 있음을 시사한다.
AI가 사무실에 출근하는 날이 온다면, 그 AI는 먼저 멀티태스킹하는 법을 배워야 할 것이다. CORPGEN은 그 교과서의 첫 번째 장이다.
참고 문헌 및 추가 자료
- Jaye, A. et al. (2026). CORPGEN: Simulating Corporate Environments with Autonomous Digital Employees in Multi-Horizon Task Environments. arXiv:2602.14229
- Microsoft Research Blog. (2026.02.26). CORPGEN advances AI agents for real work.
- Yao, S. et al. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. ICLR 2023. arXiv:2210.03629
- Xie, T. et al. (2024). OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. NeurIPS 2024.
- Microsoft UFO2: Desktop AgentOS for Windows automation. GitHub
- Mem0: AI Memory Layer. mem0.ai