내일 우리 매장에 우산이 몇 개 팔릴까? 반세기 동안 이 질문에 답하려면 데이터마다 모델을 새로 만들어야 했다. 구글 TimesFM은 LLM이 글로 했던 일을 시계열에 그대로 해냈다 — 한 번 학습하고, 처음 보는 데이터를 추가 학습 없이 예측한다. 통계학의 역사부터 2026년 GIFT-Eval 1위 TimesFM 2.5까지, 시계열 예측의 '파운데이션 모델 혁명'을 쉽게 풀어본다.
코어닷투데이2026-06-1832분
내일, 우산이 몇 개 팔릴까?
서울의 한 편의점 점주를 상상해 봅시다. 그는 매일 아침 같은 고민을 합니다. "오늘 우산을 몇 개나 들여놔야 하지?"
너무 적게 주문하면 비 오는 날 품절로 손님을 놓칩니다. 너무 많이 주문하면 창고에 재고가 쌓여 돈이 묶입니다. 그가 가진 단서는 단 하나, 과거의 판매 기록입니다. 어제는 3개, 그제는 1개, 지난주 비 오는 날엔 12개… 이 숫자들의 행렬을 보고 '내일'을 맞혀야 합니다.
이게 바로 시계열 예측(time-series forecasting) 입니다. 시간 순서대로 찍힌 숫자들(매출, 전력 사용량, 주가, 환자 수, 웹 트래픽…)을 보고 그 다음을 맞히는 일. 세상에서 가장 오래되고, 가장 돈이 되고, 동시에 가장 풀기 어려운 문제 중 하나입니다.
그런데 2024년, 구글 리서치가 흥미로운 일을 해냈습니다. ChatGPT가 "한 번 학습하고 처음 보는 문장도 척척 답하는" 방식으로 언어를 정복했듯이, 시계열에도 똑같은 마법을 부린 모델을 내놓은 겁니다. 이름은 TimesFM(Time-series Foundation Model). 편의점 점주의 판매 기록이든, 발전소의 전력 수요든, 한 번도 본 적 없는 데이터를 추가 학습 없이(zero-shot) 예측합니다.
이 글은 그 모델이 왜 중요한지를, 반세기에 걸친 예측의 역사부터 2026년 오늘의 현장까지 따라가며 풀어봅니다. 결론부터 말하면 — TimesFM은 시계열 예측이 맞이한 'GPT 모먼트' 입니다.
1. 옛날 방식: 데이터마다 모델을 새로 만들던 시대
TimesFM이 왜 특별한지 이해하려면, 먼저 그 전까지 사람들이 어떻게 일했는지를 알아야 합니다.
전통적인 예측은 이런 식이었습니다. 편의점 우산 매출을 예측하고 싶다? 그러면 우산 매출 데이터만 가지고, 우산 전용 모델을 처음부터 학습시킵니다. 옆 가게 생수 매출을 예측하고 싶다? 생수 데이터로 또 다른 모델을 처음부터 만듭니다. 발전소 전력 수요? 그것도 별도 모델.
❗
문제
새 데이터셋이 생길 때마다 모델을 처음부터 학습하고 검증해야 했다. 구글의 표현을 빌리면 "길고 복잡한 학습·검증 사이클"이 매번 반복됐다.
🔁
악순환
데이터 정제 → 모델 선택 → 하이퍼파라미터 튜닝 → 학습 → 검증 → 배포. 한 번의 예측을 얻기 위해 수 주의 ML 프로젝트가 필요했다.
💸
결과
전문 데이터 과학자가 있는 큰 회사만 제대로 된 예측을 누렸다. 작은 가게의 점주에게 '나만의 예측 모델'은 사치였다.
이걸 LLM 세계에 비유하면 이렇습니다. 번역을 하고 싶을 때마다 번역 전용 모델을, 요약을 하고 싶을 때마다 요약 전용 모델을 처음부터 학습시키던 시절이 있었죠. 그런데 GPT가 등장하면서 모든 게 바뀌었습니다. 거대한 모델 하나를 한 번 학습시켜 놓으면, 번역도 요약도 코딩도 처음 보는 작업까지 그냥 시키면 됩니다. 이게 '파운데이션 모델(foundation model)'의 힘입니다.
첫째, 딥러닝은 시계열에서 오랫동안 졌습니다. 2018년 M4 대회는 충격적이었습니다. 이미지와 언어를 정복한 신경망이, 50년 된 통계 공식에 무릎을 꿇었으니까요. 우승작조차 순수 신경망이 아니라 통계와 신경망을 섞은 하이브리드였습니다. 시계열 데이터는 보통 짧고(몇 년치 월별 데이터면 수십 개 점에 불과), 노이즈가 많고, 패턴이 제각각이라 데이터를 굶주린 듯 먹어치우는 딥러닝과 궁합이 나빴습니다.
둘째, 그래서 'global model'이라는 돌파구가 나왔습니다. M5에서 빛난 DeepAR(아마존)이나 N-BEATS 같은 모델의 핵심 아이디어는 이겁니다 — 시계열 하나하나에 모델을 따로 만들지 말고, 수많은 시계열을 한꺼번에 학습시킨 모델 하나로 모두를 예측하자. 비슷한 상품 수천 개의 판매 패턴을 한 모델이 같이 배우면, 데이터가 적은 신상품도 잘 예측할 수 있었습니다.
이 'global model' 아이디어가 바로 파운데이션 모델로 가는 징검다리였습니다. 한 발짝만 더 나아가면 됩니다 — 수천 개가 아니라 수십억 개의 시계열을 학습시키고, 학습에 쓰지 않은 완전히 새로운 데이터까지 예측하게 만들면? 그게 TimesFM입니다.
3. 왜 하필 '디코더 온리'인가: GPT의 설계를 빌려오다
TimesFM의 부제는 "A decoder-only foundation model for time-series forecasting" — '디코더 온리' 파운데이션 모델입니다. 이 'decoder-only'라는 표현, 어디서 많이 들어봤죠? 맞습니다. GPT 계열 LLM의 바로 그 구조입니다.
LLM이 글을 쓰는 방식을 떠올려 봅시다. GPT는 "나는 오늘 아침에"까지 보고 그 다음 단어를 예측합니다. 그 단어를 붙이고, 다시 다음 단어를 예측하고… 이렇게 왼쪽에서 오른쪽으로, 다음을 계속 이어 붙이며 문장을 완성합니다. 이때 핵심 규칙이 하나 있습니다 — 미래를 미리 훔쳐보면 안 된다(causal attention, 인과적 어텐션). 각 단어는 자기 앞의 단어들만 보고 예측해야 합니다. 당연하죠, 예측이란 게 원래 미래를 모르는 상태에서 하는 거니까요.
TimesFM은 이 구조를 시계열에 그대로 가져왔습니다. 단어 대신 숫자를 이어 붙인다는 것만 다릅니다.
핵심 통찰: 시계열 예측은 본질적으로 "과거를 보고 다음을 이어 쓰는" 작업이다. 이건 GPT가 글을 쓰는 방식과 정확히 같다.
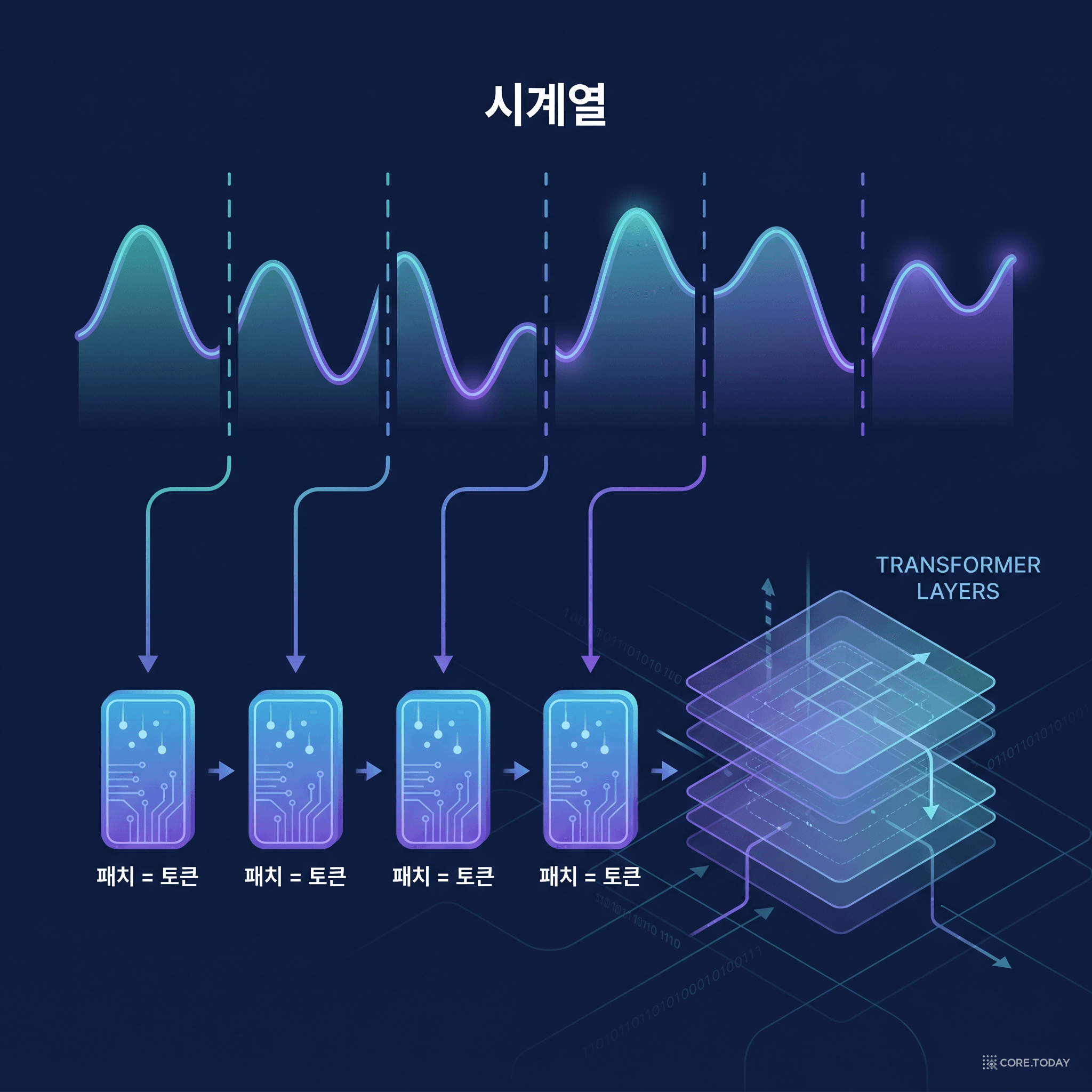
그런데 한 가지 영리한 변형이 들어갑니다. 바로 '패칭(patching)' 입니다.
패치 = 시계열의 '단어'
LLM이 글자가 아니라 토큰(단어 조각) 단위로 글을 다루듯, TimesFM은 데이터 점 하나하나가 아니라 '패치(patch)' 단위로 시계열을 다룹니다. 패치란 연속된 시간 점들을 한 덩어리로 묶은 것입니다.
예를 들어 32개의 연속된 데이터 점을 하나의 패치로 묶으면, 이 패치 하나가 GPT의 '토큰' 하나처럼 작동합니다. 이렇게 하는 이유는 두 가지입니다.
점 하나 = 토큰 하나 (나쁜 방식)
패치 하나 = 토큰 하나 (TimesFM)
긴 시계열은 토큰이 수천 개 → 트랜스포머가 감당 못 함
32점씩 묶으면 토큰 수가 1/32로 → 긴 맥락도 처리
점 하나엔 정보가 빈약 (숫자 한 개)
패치엔 '추세·기울기·변동' 같은 모양 정보가 담김
한 번에 한 점씩 → 예측이 굼뜨고 오차 누적
덩어리 단위로 빠르게 처리
패치를 만드는 과정은 이렇습니다. 32개 점으로 된 패치가 들어오면, 잔차 연결(residual connection)이 있는 작은 신경망(MLP) 이 이 덩어리를 트랜스포머가 이해하는 벡터로 변환합니다. 여기에 위치 정보(positional encoding) 를 더해 "이게 몇 번째 패치인지"를 알려준 뒤, 여러 층의 트랜스포머에 통과시킵니다. 딱 GPT가 단어를 처리하는 방식 그대로죠.
4. TimesFM만의 결정적 한 수: 입력보다 '긴' 출력
여기까지는 "GPT를 시계열에 옮겼다"는 이야기입니다. 그런데 TimesFM에는 LLM과 결정적으로 다른 설계 하나가 있습니다. 이게 이 모델의 진짜 핵심입니다.
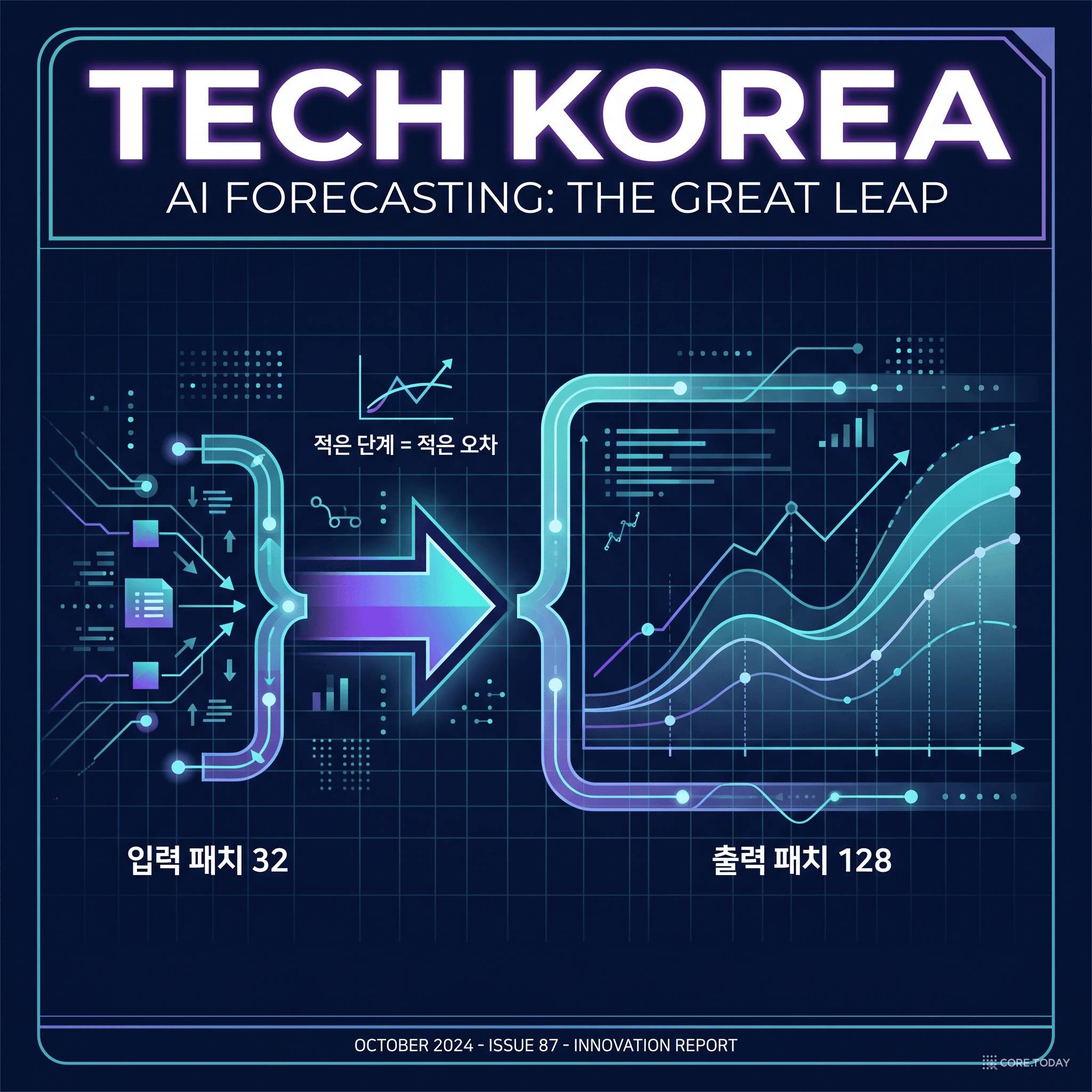
GPT는 단어를 딱 한 개씩 생성합니다. 토큰 하나 → 그 다음 토큰 하나 → 또 그 다음 하나. 그런데 TimesFM은 다릅니다. 입력 패치는 32점이지만, 출력 패치는 128점입니다. 즉 32점을 보고 한 번에 128점의 미래를 예측합니다.
자기회귀 방식(앞의 예측을 보고 그 다음을 예측하는 방식)의 고질병은, 한 번 틀린 예측이 그 다음 예측의 입력이 되어 오차가 눈덩이처럼 불어난다는 점입니다. 예측을 100번 이어 붙이면, 100번의 작은 실수가 쌓여 마지막엔 완전히 엉뚱한 값이 나옵니다.
TimesFM은 한 번에 128점씩 내뱉으니, 같은 길이를 예측해도 이어 붙이는 횟수가 확 줄어듭니다. 예를 들어 512점 앞을 예측한다면:
한 점씩 (LLM 방식)
512번 반복 → 오차 폭증
32점 출력 패치
16번 반복
128점 출력 패치 (TimesFM)
단 4번 반복 → 오차 최소
논문 저자들은 이를 "TimesFM 설계의 핵심 결정 중 하나이자, LLM과 가장 다른 점" 이라고 못박았습니다. 언어는 한 단어씩 신중하게 골라야 하지만, 미래 예측은 긴 구간을 한 번에 그려내는 게 오히려 정확하다는 것입니다.
정리하면, TimesFM은 GPT의 뼈대(디코더 온리 + 인과적 어텐션)에, 시계열에 맞는 두 가지 변형(패칭 + 긴 출력 패치)을 더한 모델입니다.
5. 100억 개의 시간 점으로 키운 2억 파라미터
좋은 구조만으로는 부족합니다. GPT를 GPT답게 만든 건 결국 인터넷 전체에 가까운 어마어마한 학습 데이터였죠. TimesFM도 마찬가지입니다. 문제는 — 시계열에는 '인터넷' 같은 거대한 공개 데이터가 없다는 점이었습니다.
글은 위키피디아, 책, 웹페이지로 수조 단어를 모을 수 있습니다. 하지만 "온갖 도메인의 시계열 데이터"는 흩어져 있고, 양도 적고, 대부분 비공개입니다. 구글 팀은 이 문제를 영리하게 풀었습니다.
1000억학습에 쓴 실제 시간 점100 billion real-world time-points
2억파라미터 수LLM보다 수백 배 작다
32 / 128입력 / 출력 패치 길이출력이 입력보다 길다
데이터의 출처가 흥미롭습니다.
구글 트렌드(Google Trends) — 사람들이 무엇을 검색하는지. '다이어트'는 매년 1월에 치솟고, '우산'은 장마철에 뜁니다. 사회 전체의 관심사가 만들어내는 거대한 시계열 패턴의 보고입니다.
위키피디아 페이지뷰(Wikipedia Pageviews) — 어떤 문서를 사람들이 언제 보는지. 실세계의 수요·관심 신호가 시간에 따라 어떻게 출렁이는지 담겨 있습니다.
합성 데이터(synthetic data) — 사인파, 추세, 계절성 같은 '시계열의 기본 문법'을 인공적으로 만들어 모델에게 가르쳤습니다.
공개 데이터셋 — 교통량, 날씨, 전력 수요 등 다양한 도메인의 실제 데이터.
여기서 주목할 점. TimesFM은 단 2억 개의 파라미터입니다. 수천억~조 단위 파라미터를 가진 LLM에 비하면 장난감처럼 작습니다. 그런데도 처음 보는 데이터에서 최고 수준의 예측을 해냅니다. 시계열의 '문법'은 언어의 문법보다 훨씬 단순하다는 뜻이기도 하고, 잘 고른 데이터와 영리한 구조가 무작정 큰 크기를 이긴다는 교훈이기도 합니다.
6. 성적표: 학습도 안 한 데이터에서 '전문가'를 이기다
이론은 충분합니다. 그래서, 실제로 잘 맞히나요? 여기가 가장 놀라운 대목입니다.
TimesFM의 평가 방식은 가혹합니다. 모델은 테스트 데이터를 학습 때 단 한 번도 본 적이 없습니다(zero-shot, 제로샷). 반면 비교 대상인 전통 모델들은 바로 그 데이터로 정식 학습을 마친 상태입니다. 비유하자면, 시험 문제를 미리 풀어본 학생들 사이에, 처음 보는 시험지를 받아든 전학생을 집어넣은 셈입니다.
결과는 이랬습니다.
상대 (모두 해당 데이터로 학습함)
TimesFM (제로샷, 학습 안 함)
ARIMA, ETS 등 통계 모델
명확히 능가
DeepAR, PatchTST 등 딥러닝 모델
대등하거나 능가
GPT-3.5 (llmtime 프롬프트 방식)
압도 — 게다가 크기는 수십~수백 배 작다
특히 두 가지가 화제였습니다.
첫째, Monash 예측 아카이브. 수만 개의 시계열, 다양한 도메인을 모은 표준 벤치마크입니다. 여기서 TimesFM은 제로샷으로, 그 데이터로 정식 학습한 DeepAR·PatchTST와 대등하거나 더 나은 성적을 냈습니다.
둘째, "LLM에게 숫자를 읽혀보자"는 시도를 이겼습니다. TimesFM 이전에도 "거대 LLM에게 숫자를 텍스트로 줘서 예측시키자"는 아이디어(llmtime)가 있었습니다. GPT-3.5에게 "1, 3, 2, 5, 4, …" 같은 숫자열을 주고 다음을 맞히게 한 거죠. TimesFM은 이 거대 LLM 방식을 수십 배 작은 몸집으로 압도했습니다. 교훈은 분명합니다 — 시계열은 시계열 전용으로 학습해야 잘한다. 언어 모델에게 숫자를 읽히는 건 우회로일 뿐입니다.
장기 예측(ETT 데이터셋, 96~192점 앞을 내다보는 과제)에서도 TimesFM은 정식 학습한 PatchTST에 필적하면서, 제로샷 LLM들은 크게 따돌렸습니다.
한 줄 요약: "공부 안 하고 처음 본 시험에서, 미리 공부한 전문가들과 맞먹거나 이겼다." 이게 파운데이션 모델이 시계열에 의미하는 바입니다.
7. 2026년의 TimesFM: 더 작아지고, 더 길게 보고, 1등을 찍다
TimesFM은 2024년에 멈추지 않았습니다. 2026년 현재, 이야기는 훨씬 더 흥미로워졌습니다.
TimesFM 2.5 — 작아졌는데 더 강해졌다
2025년 가을 공개된 TimesFM 2.5는 이전 버전의 통념을 뒤집었습니다.
#1GIFT-Eval 제로샷 1위점 예측·확률 예측 양쪽 모두
500M → 200M파라미터 감소더 작아졌다
16,384컨텍스트 길이훨씬 긴 과거를 본다
GIFT-Eval은 시계열 파운데이션 모델들을 줄 세우는 2026년의 표준 리더보드입니다. TimesFM 2.5는 여기서 점 예측 정확도(MASE)와 확률 예측 정확도(CRPS) 양쪽 모두에서 제로샷 1위를 차지했습니다. 더 놀라운 건, 파라미터를 500M에서 200M으로 줄였는데도 더 큰 전작(TimesFM 2.0)을 이겼다는 점입니다. 그리고 컨텍스트 길이가 16,384점으로 늘어나, 훨씬 긴 과거를 보고 더 멀리 내다볼 수 있게 됐습니다.
TimesFM-ICF — 예제 몇 개로 '전문가'가 되다
또 하나 주목할 진화는 'few-shot(퓨샷)' 능력입니다. LLM에게 예시 몇 개를 보여주면(in-context learning) 갑자기 그 작업을 잘하게 되는 거, 다들 아시죠? 구글은 이걸 시계열에도 이식했습니다. TimesFM-ICF(In-Context Fine-tuning).
핵심은 이렇습니다. 정식 재학습 없이, 관련된 과거 사례 몇 개를 입력에 같이 넣어주기만 하면 모델이 그 자리에서 특정 작업에 맞춰 적응합니다.
예측할 시계열 우리 매장 우산 매출
+
비슷한 사례 몇 개 다른 매장의 우산 패턴
→
맞춤 예측 재학습 0번
이 방식으로 기본 TimesFM 대비 6.8% 정확도 향상을 얻었고, 23개의 처음 보는 데이터셋에서 일관되게 개선됐습니다. 결정적으로, 정식 재학습(supervised fine-tuning) 수준의 성능을, 재학습 없이 달성했습니다. 새 예측 과제가 생길 때마다 ML 프로젝트를 띄우는 대신, 관련 예시 몇 개만 붙여주면 끝이라는 뜻입니다.
BigQuery와 Model Garden — 클릭 몇 번으로 예측
TimesFM은 이제 구글 클라우드 BigQuery와 Vertex AI Model Garden에 통합되고 있습니다. 데이터 과학자가 아니어도, SQL 한 줄이나 클릭 몇 번으로 자기 데이터에 최첨단 제로샷 예측을 돌릴 수 있게 된 겁니다. 이게 바로 1장에서 말한 편의점 점주에게도 예측이 닿는 길입니다.
8. 왜 지금 이게 중요한가: '예측의 민주화'
2026년 현재, TimesFM은 혼자가 아닙니다. 아마존의 Chronos, 세일즈포스의 Moirai, 그 밖의 여러 시계열 파운데이션 모델이 같은 길을 달리고 있습니다. 시계열 예측은 지금 "각자 모델을 만들던 시대"에서 "거대 모델 하나를 가져다 쓰는 시대"로 빠르게 넘어가는 중입니다. 마치 2020년대 초 언어 모델이 그랬던 것처럼요.
유통·리테일신상품은 판매 이력이 없어 예측이 가장 어렵다. 파운데이션 모델은 비슷한 상품 수십억 개의 패턴을 이미 알고 있어, 데이터가 거의 없는 신상품도 제로샷으로 수요를 가늠한다.
에너지전력 수요는 날씨·요일·계절이 얽힌 복잡한 시계열. 신재생에너지 비중이 늘며 변동성이 커진 2026년, 빠르고 정확한 부하 예측은 곧 비용이자 안정성이다.
제조·설비센서가 뿜어내는 진동·온도 시계열을 보고 고장을 미리 예측(예지보전). 설비마다 모델을 새로 만들던 부담을, 파운데이션 모델 하나가 덜어준다.
금융·운영현금흐름, 트래픽, 콜센터 인입량… 모든 비즈니스는 '다음 주에 얼마나'를 알고 싶어 한다. 전담 데이터 팀 없이도 그 답에 다가갈 수 있게 됐다.
핵심은 '예측의 민주화' 입니다. 예전엔 예측 모델을 제대로 굴리려면 전담 데이터 과학자, 긴 학습 파이프라인, 도메인 전문성이 모두 필요했습니다. 이제는 잘 만든 파운데이션 모델 하나에 자기 데이터를 넣기만 하면 합리적인 첫 예측이 나옵니다. 1장의 편의점 점주가 자기만의 예측 모델을 가질 수 있는 시대가, 정말로 온 겁니다.
물론 만능은 아닙니다. 갑작스러운 외부 충격(팬데믹, 정책 변화처럼 과거에 전례 없는 사건), 극단적으로 도메인 특수한 데이터, 인과관계가 중요한 의사결정에는 여전히 사람의 판단과 보조 정보가 필요합니다. 파운데이션 모델은 '무에서 시작하지 않게 해주는 강력한 출발점' 이지, 모든 예측을 자동으로 끝내주는 마법 상자는 아닙니다.
9. 마치며: 시간이라는 데이터를 읽는 법
돌아보면 이야기는 깔끔합니다.
과거 데이터마다 모델을 처음부터 만들던 50년. 딥러닝조차 통계 모델을 못 이기던 보수적인 분야.
전환 "언어에 GPT가 있다면 시계열에도?" — 디코더 온리 구조에 패칭과 긴 출력 패치를 더한 TimesFM.
현재 2026년, TimesFM 2.5가 GIFT-Eval 1위. 예제 몇 개로 적응하는 퓨샷, 클릭 몇 번으로 쓰는 클라우드 통합. 예측의 민주화.
TimesFM이 보여준 진짜 교훈은 단순한 "또 하나의 좋은 모델"이 아닙니다. '한 번 학습하고 어디에나 적용한다'는 파운데이션 모델의 패러다임이, 언어와 이미지를 넘어 '시간' 그 자체로 확장되고 있다는 신호입니다.
우리가 다루는 거의 모든 데이터는 시간 위에 찍혀 있습니다. 매출도, 트래픽도, 전력도, 환자 수도, 심지어 이 글을 읽는 당신의 행동 로그도. 그 모든 시계열을 추가 학습 없이 읽어내는 범용 모델이 손에 들어왔다는 것 — 이것이 TimesFM이 시계열 예측에 가져온 'GPT 모먼트'입니다.