들어가며: 21%에서 95%로 — 그리고 그 사이에 모델 교체는 없었다
2026년 6월 3일, Anthropic의 데이터 사이언스·데이터 엔지니어링 팀이 한 편의 글을 공개했다. 제목은 평범하다. "How Anthropic enables self-service data analytics with Claude". 그런데 안에 담긴 숫자는 평범하지 않다.
- 사내 비즈니스 분석 쿼리의 95%를 Claude가 자동 처리
- 종합 정확도 약 95%, 일부 도메인에서는 99%
- 그런데 스킬(Skills) 없이 같은 모델을 돌리면 정확도는 21%
21%와 95% 사이에 모델 업그레이드는 없었다. 같은 Claude다. 그 74%포인트의 간극을 메운 것은 더 큰 모델도, 더 비싼 GPU도 아닌 — 마크다운 문서와 데이터 거버넌스, 그리고 집요한 검증 체계였다.
이 글이 데이터 업계에서 화제가 된 이유는 단순히 수치가 인상적이어서가 아니다. 30년 넘게 업계가 실패해온 "셀프서비스 분석"이라는 오래된 약속에 대해, 처음으로 재현 가능한 설계도와 함께 — 무엇이 효과 없었는지에 대한 부정적 실험 결과(null result)까지 — 공개했기 때문이다.
이 특집에서는 이 발표를 제대로 이해하기 위해 필요한 모든 맥락을 다룬다. 왜 이런 개념이 나오게 되었는지(60년의 역사), 기존 방식과 무엇이 다른지, 왜 성능이 좋은지, 그리고 우리 조직에는 어떻게 적용할 수 있는지까지.

제1장: 30년의 약속 — 셀프서비스 분석은 왜 계속 실패했나
이 발표의 무게를 이해하려면 먼저 셀프서비스 분석(self-service analytics)이라는 꿈이 얼마나 오래, 얼마나 반복적으로 좌절되어 왔는지 알아야 한다.
"IT 부서 없이 누구나 데이터를" — 1990년부터 반복된 약속
1990
BusinessObjects "Universe" — 시맨틱 레이어의 원조. DB 테이블을 비즈니스 용어로 매핑해 "SQL 없이 질의"를 약속. 미국 특허 US5555403A. 그러나 벤더 락인과 느린 변경 대응이 발목을 잡았다
2003
Tableau — 드래그앤드롭 시각화로 "셀프서비스 BI" 시대 개막. 2019년 Salesforce가 157억 달러에 인수. 속도를 위해 시맨틱 레이어를 버리고 DB에 직접 연결 — 그 대가로 메트릭 정의가 팀별로 난립하기 시작했다
2012
ThoughtSpot — "검색하듯 데이터에 질문하라". 자연어 BI 1세대의 야심작
2019
Tableau Ask Data — 자연어 질의 기능 출시. 그러나 "필드명과 키워드를 알아야 해서 충분히 natural하지 않다"는 평가 속에 2024.2 버전부터 제품에서 제거되었다
2026
Anthropic 사내 시스템 — 분석 쿼리의 95% 자동화, 정확도 ~95%. 무엇이 달랐을까?
숫자로 보는 좌절의 역사
기술은 계속 발전했는데, 정작 조직 내 BI 도입률은 25년간 박스권에 갇혀 있었다.
Gartner는 2019년에 "2021년까지 자연어 처리와 대화형 분석이 BI 도입률을 35%에서 50% 이상으로 끌어올릴 것"이라고 예측했지만, 실현되지 않았다. Ventana Research의 David Menninger는 실패의 원인을 이렇게 정리했다: "우리는 잘못된 문제를 풀고 있었다. BI 플랫폼은 전체 인력의 25%쯤 되는 분석가를 위해 설계됐지, 일반 비즈니스 사용자를 위해 설계되지 않았다."
그 결과는 데이터 팀의 만성 병목이다:
- 애드혹 데이터 요청이 분석가 시간의 50~70%를 잠식한다 (수요가 높은 리테일·금융·테크 기준)
- 분석가는 시간의 80%를 데이터 찾기·정제·정리에 쓰고, 실제 분석은 20%에 불과하다
- 데이터 워커 시간의 44%가 비생산적 활동에 소모되고, 34%는 데이터 접근 시도 자체에 낭비된다 (IDC/Alteryx)
- 비즈니스 사용자는 데이터 요청 후 수 시간에서 수일, 때로는 수 주를 대기한다
Anthropic 원문도 이 역사를 정확히 짚으며 시작한다. 비전문가를 위해 넓고 비정규화된 테이블을 만들면 "비즈니스가 성장하면서 정의가 제각각인 중복 뷰들"이 생기고, 반대로 안전한 울타리 환경을 만들면 "롱테일 질문을 놓치고 메트릭·대시보드 비대화"로 이어진다는 것. 30년간 모두가 경험한 딜레마다.
LLM의 부상은 이 난관을 피해가는 새로운 길을 제공한다. 하지만 Claude를 웨어하우스에 그냥 연결하고 에이전트가 실행하게 두는 것은 거짓된 정밀함(false sense of precision)을 만들어낼 수 있다. — Anthropic 원문
이 문장이 이 글 전체의 출발점이다. "그냥 LLM 붙이면 되는 거 아냐?"가 왜 안 되는지부터 살펴보자.
제2장: Text-to-SQL 60년사 — 벤치마크는 풀렸는데 현실은 안 풀렸다
"자연어로 데이터베이스에 질문한다"는 아이디어는 LLM보다 훨씬 오래됐다. 사실 컴퓨터 과학에서 가장 오래된 꿈 중 하나다.
1세대: 규칙 기반 (1960s~1980s)
1961년 야구 경기 기록에 답하는 BASEBALL 시스템이 시초였고, 1972년에는 NASA 아폴로 미션의 월석 데이터를 지질학자가 자연어로 질의하는 LUNAR(William A. Woods, BBN)가 등장했다. 1980년의 CHAT-80은 Prolog 기반으로 영어 질문을 논리식으로 변환했다. 모두 수작업 규칙과 문법에 의존했고 — 다른 도메인으로 이식이 불가능해 상용화에 실패했다.
2세대: 딥러닝 (2017)
2017년 Salesforce Research의 Seq2SQL(Zhong, Xiong, Socher)이 위키피디아 테이블 기반 80,654개 질문-SQL 쌍(WikiSQL)으로 딥러닝 시대를 열었다. 강화학습을 적용해 실행 정확도를 35.9%에서 59.4%로 끌어올렸지만, 단일 테이블의 단순 SELECT-WHERE 쿼리만 다룰 수 있었다.
3세대: 벤치마크 정복 (2018~2023)
2018년 Yale의 Spider 벤치마크(Yu et al., EMNLP 2018)가 게임의 규칙을 바꿨다. 200개 데이터베이스, 138개 도메인, JOIN과 중첩 쿼리를 포함한 복잡한 SQL — 그리고 무엇보다 훈련 때 본 적 없는 DB 스키마에 일반화해야 했다.
5년 만에 12.4% → 91.2%. 벤치마크는 사실상 "풀렸다". 그런데 —
현실 점검: BIRD와 Spider 2.0의 충격 (2023~2024)
2023년 NeurIPS에 발표된 BIRD 벤치마크(Li et al.)는 학술용 장난감 DB 대신 실제 세계의 지저분한 데이터(95개 DB, 총 33.4GB, 더러운 값, 외부 지식 필요)를 가져왔다. 결과:
인간과 38%포인트 격차. 그리고 2024년 말, Spider 2.0(Lei et al., ICLR 2025 Oral)이 진짜 기업 환경 — 1,000~3,000개 이상의 컬럼, BigQuery/Snowflake 방언, 100줄 넘는 정답 SQL, dbt 프로젝트 탐색 — 을 들고 오자 성적표는 처참해졌다.
| 모델/시스템 | Spider 1.0 | BIRD | Spider 2.0 |
|---|
| GPT-4o 기반 | 86.6% | — | 10.1% |
| o1-preview (Spider-Agent) | 91.2% | 73.0% | 17.1% |
| DeepSeek-V3 | — | — | 8.78% |
같은 모델이 학술 벤치마크에서 91.2%, 기업 환경에서 17.1%. 이것이 2024년 말의 현주소였다. Spider 2.0 논문이 지목한 원인은 정확히 Anthropic이 이번 글에서 말하는 것과 겹친다: 거대한 스키마에서 올바른 컬럼을 찾지 못하고(검색 실패), 같은 개념의 정의가 충돌하고(모호성), 단발성 "질문→SQL" 패러다임으로는 다단계 탐색이 불가능하다는 것.
흥미로운 후일담: 2025~2026년 사이 Spider 2.0 리더보드는 에이전틱 시스템(탐색하고, 문서를 읽고, 자기 교정하는)의 등장으로 급상승했다. 2026년 3월 Genloop의 Sentinel Agent v2 Pro는 Spider 2.0-Snow에서 96.70을 기록했다. 단발 생성에서 에이전트 루프로의 전환 — 업계 전체가 같은 결론에 수렴하고 있다.
그리고 결정적 발견: 컨텍스트가 모델보다 중요하다
2023년 11월 data.world의 벤치마크 연구(arXiv:2311.07509)는 이 시대의 핵심 명제를 수치로 증명했다:
- GPT-4 zero-shot으로 엔터프라이즈 SQL DB에 직접 질의: 정확도 16.7%
- 같은 모델 + 지식 그래프(시맨틱 표현) 위에서: 54.2% (약 3.2배)
- dbt Labs의 재현 실험에서 시맨틱 레이어 경유 시: 83%
- Cube의 2026년 페어드 벤치마크: 시맨틱 레이어 추가만으로 3개 프런티어 모델 모두 +17~23%p, "모델 선택보다 시맨틱 레이어 유무가 분산의 거의 전부를 설명"
모델을 바꾸는 것보다 컨텍스트를 바꾸는 것이 훨씬 큰 차이를 만든다. Anthropic의 21% → 95% 이야기는 이 흐름의 가장 극적인 실증 사례다.
제3장: 데이터는 소프트웨어가 아니다 — 코딩 에이전트가 잘 되는데 분석 에이전트는 왜 안 되나
여기서 자연스러운 의문이 생긴다. Claude는 코딩을 그렇게 잘하는데, 왜 분석은 따로 이런 거대한 체계가 필요한가? SQL도 결국 코드 아닌가?
Anthropic은 이 질문에 한 장의 표로 답한다. 원문에서 그대로 가져왔다:

핵심을 정리하면:
| 단계 | 코딩 에이전트 | 분석 에이전트 |
|---|
| 컨텍스트 | 코드베이스는 대체로 잘 관리됨. README, 타입 시그니처, docstring, 커밋 히스토리가 풍부한 구조적 맥락 제공 | DB에는 수백만 개의 필드, 대부분 문서화 부실. "매출" 비슷한 개념이 수천 곳에 등장. 같은 메트릭도 팀마다 다르게 정의 |
| 생성 | 거의 모든 스펙은 여러 개의 올바른 구현을 허용 — 그럴듯한 답이 대개 유효한 답 | 구현 자체는 사소함(SQL 5~10줄). 그러나 올바른 접근은 대개 단 하나 |
| 검증 | 컴파일러, 린터, 유닛 테스트가 빠르고 결정적인 피드백 제공 | 컴파일러도, 유닛 테스트도, 그라운드 트루스도 없음. 출력이 맞는지 결정적으로 확인할 방법이 없다 |
코딩은 창의성이 보상받는 열린 솔루션 공간이고, 분석은 단 하나의 정답을 요구하는 닫힌 공간이다. 게다가 코딩의 환각은 컴파일러가 잡아주지만, 분석의 환각은 — 그럴듯한 숫자의 형태로 — 이사회 보고서까지 조용히 흘러들어간다.
3대 실패 모드
Anthropic은 부정확한 답변의 압도적 다수가 단 세 가지 원인에서 나온다는 것을 발견했다:
1
개념↔엔티티 모호성 (Concept-Entity Ambiguity)
수백만 필드 중 수백 개의 그럴듯한 후보가 있을 때, 사용자의 질문에 가장 맞는 필드를 고르지 못한다. "활성 사용자"를 측정할 때 — 어떤 행동이 "활성"인가? 사기 계정은 포함하나? 기간 기준은?
2
데이터 신선도 붕괴 (Staleness)
데이터 소스, 비즈니스 정의, 스키마는 끊임없이 변한다. 에이전트의 지식이 낡으면 — 미묘하게 틀린 답을 반환하기 시작한다. 완전히 틀린 답보다 위험하다.
3
검색 실패 (Retrieval Failure)
올바른 정보가 데이터 모델 안에 존재하고 주석까지 잘 달려 있어도, 검색 공간이 너무 광활해서 에이전트가 그냥 찾지 못한다.
주목할 점: 세 가지 모두 SQL 작성 능력과 무관하다. Anthropic의 표현을 빌리면, "사용자의 질문을 데이터 모델의 구체적이고 최신인 엔티티에 매핑하고 그것을 다루는 올바른 방법을 아는 것 — 그게 되면 SQL은 사소해진다(trivial)."
"활성 사용자가 몇 명인가요?"의 함정
1번 실패 모드가 어떤 것인지, 원문의 설계 다이어그램이 잘 보여준다. 평범한 스타 스키마에서조차 "활성"의 정의는 세 갈래로 갈라진다:
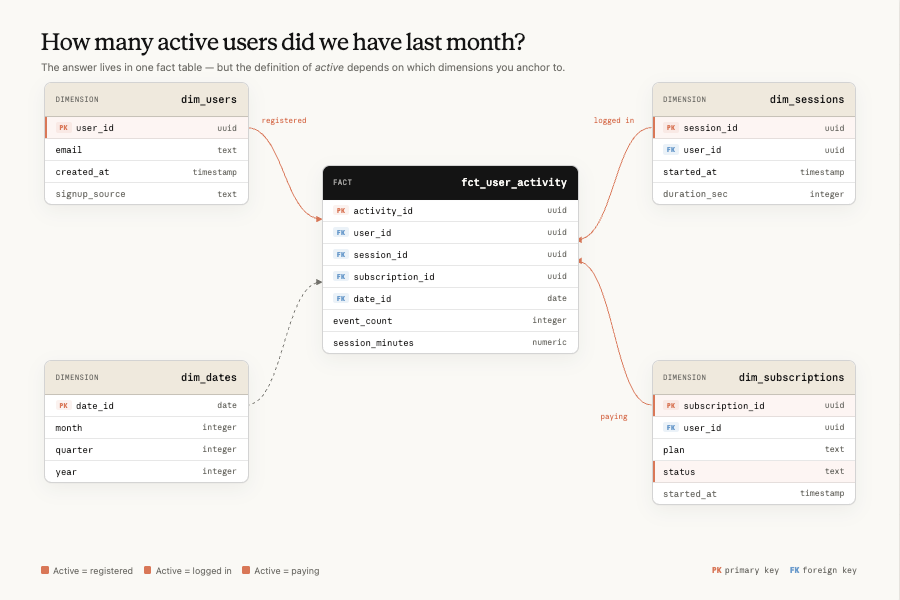
직접 체험해보자. 아래 탐험기에서 세 가지 정의 선택만으로 답이 얼마나 달라지는지 확인할 수 있다:
이것이 Text-to-SQL 연구가 "schema linking 문제"라고 불러온 것의 실체이고, 실제 대규모 환경에서 전체 실패의 60% 이상을 차지한다는 연구 보고(LinkAlign, arXiv:2503.18596)도 있다. 두 답이 모두 기술적으로 맞으면서 상황적으로는 틀릴 수 있다 — 이것이 분석 에이전트 문제의 본질이다.
제4장: 에이전틱 분석 스택 — 4계층 설계도 해부
이제 본론이다. Anthropic은 세 가지 실패 모드를 공격하기 위해 4개의 계층으로 구성된 스택을 구축했다. 원문의 설계도를 그대로 가져왔다:

각 계층을 클릭하며 탐험해보자:
이제 한 층씩 내려가며 자세히 살펴본다.
4-1. Data Foundations: "매출"이 40개가 아니라 1개여야 한다
가장 아래층은 웨어하우스 그 자체 — 데이터 모델, 변환, 테스트, 메타데이터다. Anthropic의 첫 번째 메시지는 의외로 보수적이다: 차원 모델링(dimensional modeling), 신선도·완전성 검사 같은 전통적 데이터 엔지니어링 관행은 그 어느 때보다 중요하다.
달라진 것은 데이터 모델의 최종 사용자다. 더 이상 데이터 전문가(데이터 사이언티스트)가 아니라, 다양한 수준의 사용자를 대리하는 에이전트다. 사용자는 결과의 정합성을 스스로 검증할 수 없다 — 그래서 시스템이 검증을 내장해야 한다.
핵심 실천은 세 가지다:
- 정규 데이터셋(canonical datasets)을 만들어라: 가장 흔한 실패는 에이전트가 "제품 X의 매출"이라는 개념을 단 하나의 올바른 테이블·컬럼·메트릭 정의에 매핑하지 못하는 것 — 대개 미묘하게 다른 구현의 후보가 여럿 존재하기 때문이다. 해법은 적지만 강하게 거버넌스되는 논리 모델이다. 명확한 소유자가 있고, 바로 소비 가능하고, 발견 가능한 단일 진실 공급원 데이터셋을 소수만 큐레이션하고, 유사 중복은 공격적으로 폐기한다.
- 표준을 강제하라: 거버넌스는 도구(에이전트가 구조적으로 먼저 라우팅됨), CI(우회하는 변경은 리뷰 실패), 위임(다운스트림 팀은 거버넌스 레이어 위에 구축하거나 사유를 설명)으로 강제될 때만 유지된다. 강제 없는 거버넌스는 곧 다시 "후보 40개" 상태로 부패한다.
- 메타데이터를 일급 제품으로 다뤄라: 코딩 에이전트가 잘 작동하는 이유 중 하나는 코드베이스가 읽기 쉽기(legible) 때문이다. README, 타입 시그니처, docstring처럼 — 웨어하우스도 컬럼·테이블 설명, 그레인 문서, 유효값 범위, 리니지, 소유권, 모델 티어링이 변환 코드만큼 엄격하게 관리되면 그만큼 읽기 쉬워질 수 있다.
4-2. Sources of Truth: 30년 만에 부활한 시맨틱 레이어
두 번째 층은 에이전트가 웨어하우스를 항해할 때 참조하는 표면들이다. 신뢰도 내림차순으로 네 가지:
① 시맨틱 레이어 — 컴파일된 메트릭·차원 정의. 질문이 정의된 메트릭에 깔끔하게 매핑되면, 에이전트는 함수를 호출하고 하나의 숫자를 받는다. 회사의 다른 모든 화면이 만들어내는 것과 같은 숫자를. Anthropic의 에이전트는 스킬 지시에 의해 시맨틱 레이어를 항상 먼저 시도하도록 구조적으로 강제된다.
1990년 BusinessObjects의 Universe로 태어나, Tableau 시대에 "너무 느리고 독점적"이라며 버려졌다가, 2012년 Looker의 LookML로 "코드로서의 시맨틱"으로 부활하고, 2021년 Benn Stancil의 "The missing piece of the modern data stack"으로 재점화된 그 시맨틱 레이어다. 30년의 우여곡절 끝에 — AI 에이전트의 등장이 시맨틱 레이어를 "선택"에서 "필수"로 바꿨다. 제2장에서 본 수치(16.7% vs 54.2~83%)가 그 증거다.
여기서 Anthropic의 정직한 실패 공유 하나가 빛난다:
우리가 시도했지만 효과가 없었던 아이디어: LLM에게 raw 테이블과 쿼리 로그로부터 메트릭 정의를 자동 생성시켜 시맨틱 레이어를 부트스트랩하는 것. 그럴듯해 보이는 정의가 생성됐지만 — 우리가 제거하려던 바로 그 모호성을 그대로 인코딩하고 있었고, 사람이 큐레이션한 더 작은 레이어 대비 평가에서 net-negative였다. 따라서 문서는 Claude로 생성하되, 정의의 주인은 사람이어야 한다.
② 리니지와 변환 그래프 — 시맨틱 레이어가 질문을 커버하지 못할 때, 리니지와 테이블 랭킹(참조 횟수 기반)은 어떤 상위 모델이 개념을 공급하는지, 어떤 모델이 폐기되었는지, 어떤 모델이 같은 그레인을 공유하는지 추론하게 해준다. "메트릭을 모르겠다"를 "어떤 거버넌스 모델에서 집계해야 하는지는 안다"로 바꿔주는 층이다.
③ 쿼리 코퍼스 — 대시보드, 노트북, 과거 분석의 SQL 기록. 직관적으로는 고가치다 — 이미 올바르게 답변된 모든 질문의 기록이니까. 그런데 실험 결과는 충격적이었다 (제5장에서 자세히). 결론만 먼저: 쿼리 히스토리는 에이전트가 직접 읽는 진실 공급원이 아니라, 사람이 큐레이션할 원재료로 취급하라.
④ 비즈니스 맥락 — 대부분의 팀이 건너뛰는 층이고, Anthropic 스스로 "가장 오래 과소평가했다"고 고백한 층. 비즈니스를 이해하지 못하는 에이전트는 사용자가 물은 것에는 답하지만, 사용자가 의도한 것에는 답하지 못한다. "Q2 런칭"이 특정 제품을 가리킨다는 것, 두 팀이 같은 용어를 다르게 정의한다는 것, 목요일에 이사회가 있어서 이 질문이 나왔다는 것 — Anthropic은 인덱싱된 문서, 로드맵, 의사결정 로그, 조직 구조로 구성된 사내 지식 그래프를 에이전트에 연결해 이 격차를 메운다.
4-3. Skills: 21%를 95%로 만든 마크다운
세 번째 층이 이 글의 주인공이다. 신뢰의 원천이 에이전트의 선언적 지식(메트릭이 무엇을 의미하는가)이라면, 스킬은 절차적 지식(어떤 소스를 어떤 순서로 참조하고, 모호한 데이터를 어떻게 다루고, 완성된 분석이 어떤 모습인가)이다.
Claude Code에서 스킬은 에이전트가 필요할 때 읽는 마크다운 폴더다. 2025년 10월 Anthropic이 발표한 Agent Skills 개념 — SKILL.md 파일에 YAML 메타데이터와 지시문을 담고, 점진적 공개(progressive disclosure) 방식으로 시작 시에는 몇십 토큰의 메타데이터만 로드했다가 관련 작업이 요청되면 전체를 로드하는 구조다. Simon Willison이 "MCP보다 더 큰 사건일 수 있다"며 "스킬의 캄브리아기 대폭발"을 예견했던 그것이다.
그리고 이번 글은 그 예견에 대한 첫 대규모 정량 검증이다:

Anthropic의 스킬 설계에는 뚜렷한 패턴이 있다. 쌍(pairwise)으로 만든다:
Anthropic의 페어 스킬 구조
Knowledge Skill
얇은 라우터
"시맨틱 레이어 먼저. 커버 안 되면 이 도메인의 참조 문서 ~30개로 범위 축소." 수백만 필드의 검색 공간을 수십 개 문서로 좁힌다 — 검색 실패에 대한 답.
Unbook Skill
분석 프로세스
시니어 분석가의 절차: 질문 명확화 → 소스 탐색(지식 스킬 경유) → 쿼리 실행 → 적대적 리뷰 루프. 리텐션 곡선, 비율 분해, 퍼널 분석 등 재사용 패턴 12종 동봉.
참조 문서는 LLM의 검색을 위해 쓰여진다. 테이블의 그레인·범위·제외 조건, 함정의 메커니즘("알려진 무료 이메일 도메인은 제외하되 anthropic.com 같은 커스텀 도메인은 유지"), 명시적 라우팅 트리거("실험 lift에 관한 질문이면… raw 이벤트 카운트에는 사용 금지") — 단, 금방 낡아버리는 처방적 레시피는 넣지 않는다.
가장 중요한 교훈: 스킬은 썩는다
이 섹션에서 가장 값진 대목은 실패담이다:
스킬 문서는 매일 변하는 데이터 모델을 설명하므로, 능동적으로 유지보수하지 않으면 몇 주 안에 틀린 문서가 된다. 우리는 오프라인 정확도가 출시 시점 ~95%에서 한 달 만에 ~65%로 표류하는 것을 지켜본 뒤에야 이것을 엔지니어링 문제로 취급하기 시작했다.
해법은 콜로케이션(colocation)이다. 스킬 마크다운을 변환 모델과 같은 저장소에 두어, 모델을 바꾸는 PR이 곧 그 모델을 설명하는 문서를 업데이트하는 PR이 되게 한다. 코드 리뷰 훅이 스킬 파일을 건드리지 않은 리포팅 모델 변경을 자동으로 지적한다. 현재 Anthropic의 데이터 모델 PR 중 약 90%가 같은 diff 안에 스킬 변경을 포함한다.
그리고 일관성: 같은 스킬이 Slack에서든, IDE에서든, 대시보드 도구에서든, 독립 에이전트 세션에서든 반드시 같은 답을 내야 한다. Anthropic은 단일 정본(데이터 repo)을 두고 머지 시 플러그인 마켓플레이스(IDE용), 클라우드 스토리지(호스팅 앱용), MCP 리소스로 자동 동기화한다.
4-4. Validation: 어떤 실패가 아직 새고 있는지 찾아라
마지막 층은 검증이다. Anthropic이 목격한 흔한 패턴: 데이터 팀이 정교한 분석 환경을 구축해놓고, 정작 그 에이전트의 정확도를 이해할 프로세스는 없다.
오프라인 평가(offline evals)는 단순한 질문-정답 쌍이다. ML 모델의 오프라인 테스트와 같다 — 온라인 성능을 말해주진 않지만, 치명적 공백이 있는지는 알려준다. Anthropic은 두 종류를 운영한다:
- 대시보드 기반 평가: Claude가 자동 생성(사람이 검증)하며 가장 흔한 스테이크홀더 질문을 커버
- 롱테일 평가: Claude에 비즈니스 맥락(로드맵, 테이블 문서)을 주입해 도메인 전체의 그럴듯한 질문을 생성. 또한 스테이크홀더가 스레드에서 에이전트를 교정할 때마다 그 교정을 평가 후보로 수확
운영 원칙들이 실전적이다:
- 그라운드 트루스를 고정하라: 라이브 데이터 기반 평가는 숫자가 움직이는 순간 낡는다. 모든 평가를 스냅샷 날짜에 고정하거나, 안정적인 fact 테이블 기준으로 작성하거나, 채점자가 숫자 대신 쿼리를 평가하게 하라.
- 결과를 테스트 로그가 아니라 텔레메트리처럼 저장하라: 모든 실행이 스킬 버전, git SHA, 모델 ID, 어서션별 통과 여부, 토큰 수, 소요 시간과 함께 웨어하우스 테이블에 쌓인다. "그 변경이 도움이 됐나?"가 쿼리 한 방이 되고, 단일 CI 실행으로는 못 잡는 느린 회귀를 시계열로 잡는다.
- 도메인별 출시 게이트: 도메인 소유자는 자기 슬라이스의 평가 세트가 임계값(초기 ~90%)을 넘기 전까지 스테이크홀더에게 에이전트를 공개할 수 없다. 사용자가 실패를 목격하기 전에 참조 문서를 고치도록 강제하는 장치다.
- 오프라인 평가 정확도는 ~100%여야 한다: 모든 정답이 시맨틱 레이어를 경유해야 한다. 이 수치는 "시스템이 틀리지 않는다"가 아니라 "명백한 공백은 없다"는 의미일 뿐이다.
제5장: 검증의 과학 — null result가 로드맵 몇 달을 바꿨다
이 글이 단순한 자랑이 아니라 엔지니어링 문서로 평가받는 이유가 이 장에 있다. Anthropic은 스킬에 관한 모든 구조적 결정(어떤 소스를 노출할지, 서브에이전트가 지연시간 값을 하는지, 스킬 두 개를 합칠지)을 오프라인 평가 세트를 고정하고 정확히 하나의 변수만 바꿔 통과율을 비교하는 ablation으로 내린다. 한 번의 실험은 한 시간이면 끝나고, 수많은 논쟁을 대체한다.
직접 실험해보자:
가장 유용했던 실험은 실패한 실험이었다
Anthropic이 "가장 유용한 ablation"으로 꼽은 것은 부정적 결과다. 시나리오를 따라가 보자:
가설
과거에 올바르게 답변된 SQL 수천 개(대시보드·변환·노트북 전체)에 대한 직접 grep 접근을 주면 정확도가 오를 것이다
실험
접근 권한 부여 후, 트랜스크립트에서 에이전트가 답변 전에 실제로 그 파일들을 읽었는지까지 검증
결과
정확도 변화: 어느 방향으로든 1%포인트 미만
교란 변수 점검
틀린 문제들의 정답이 실제로 코퍼스 안에 있었나? → 약 80%는 있었다. "정답 존재"가 "이제 맞춤"을 예측했나? → 아니오, 플립률은 평평했다
결론
정보는 거기 있었고, 에이전트는 그것을 봤고, 그래도 쓰지 못했다. 병목은 접근(access)이 아니라 구조(structure) — 질문을 올바른 엔티티에 매핑하는 능력이었다. 이 한 번의 실험이 몇 달치 로드맵을 다시 썼다
이 발견은 RAG 시대의 통념 — "더 많은 컨텍스트 = 더 나은 답" — 을 정면으로 반박한다. 비구조화된 검색은 새 질문을 올바른 선례에 매핑하지 못한다. 효과가 있었던 것은 그 코퍼스를 도메인별 구조화된 참조 문서와 재사용 가능한 분석 패턴으로 증류(distill)하는 것이었다.
실패 목록을 기록하라
Anthropic은 "효과 없었던 것들의 짧은 목록"을 유지한다. 공개된 두 가지:
- 문서 정제 라운드를 계속 쌓는 것: 어느 지점을 지나자 3회 연속 net-negative. 문서는 길어졌지만, 나아지지 않았다.
- 적대적 리뷰어를 저렴한 모델로 교체: 정확도 이득 대부분을 잃고, 속도는 거의 빨라지지 않았다.
부정적 결과는 기록 비용이 저렴하고, 다음 사람이 같은 실험을 반복하는 것을 막는다. 모든 의미 있는 스킬 수정은 관련 평가 슬라이스의 before/after 실행을 거치고, 그 델타가 PR 설명에 들어간다. "문서를 개선했다"는 주장을 정직하게 유지하는 장치다.
온라인 검증: 운영 중인 시스템 감시하기
- 적대적 리뷰: 최종 답변의 모든 기저 가정을 공격적으로 도전하는 Claude 스킬. 평가 세트 기준 정확도 +6% — 단, 토큰 +32%, 지연 +72%의 비용. 트레이드오프를 숨기지 않고 가격표째 공개한 점이 인상적이다.
- 출처 푸터(provenance footer): 모든 응답에 어느 소스 등급에서 왔는지(시맨틱 레이어 › 큐레이션 참조 › raw 테이블), 데이터가 얼마나 신선한지, 모델 소유자가 누구인지 표시. 답을 더 정확하게 만들진 않지만, 소비자가 얼마나 신뢰할지 판단하게 해준다. "raw 테이블, 신선도 불명" 푸터는 위로 전달하기 전에 검증하라는 신호다.
- 수동 모니터링: 시맨틱 레이어를 경유해 해결된 쿼리 비율, 그리고 교정 언어("그 테이블 아니에요", "fraud 필터 빠졌어요")를 쓰는 응답 비율 — 두 신호를 주간 대시보드로 추적.
- 능동적 교정 수확: 몇 시간마다 스케줄된 에이전트가 스테이크홀더 채널을 스캔해 교정 발언을 찾고, 관련 참조 문서에 대한 한 줄짜리 수정을 작성해 도메인 소유자 태그와 함께 PR을 연다. 수정 경로는 의도적으로 지루하게 — 마크다운 수정, 머지, 자동 동기화. 같은 교정이 오프라인 평가 세트로도 피드백된다.
그리고 정직한 한계 고백: 이 모든 것이 완전히 잡지 못하는 실패 모드는 "조용한 실패" — 틀렸지만 그럴듯해 보여서 아무 이의 없이 사용되는 답이다. 출처 푸터, 경영진 보고용 답변에 대한 명시적 인간 승인, 도메인별 핵심 KPI를 매일 공식 대시보드와 대조하는 상시 평가가 완화책이지만, "아직 견고한 해법은 없다"고 인정한다.
제6장: 다른 회사들은 어떻게 했나 — 업계 수렴의 증거
Hacker News의 한 댓글은 시큰둥했다: "Uber가 반년 전에 비슷한 글을 썼다. 특별할 것 없다." 절반은 맞다. 실제로 여러 빅테크가 같은 문제를 풀어왔고 — 그래서 더 흥미롭다. 서로 다른 회사들이 독립적으로 같은 결론에 수렴했기 때문이다.
| 회사/시스템 | 접근법 | 성과 | 핵심 교훈 |
|---|
| Uber QueryGPT (2024.9) | 도메인별 Workspace 큐레이션 + Intent/Table/Column Prune 에이전트 + RAG | 쿼리 작성 10분 → 3분, 사용자 78% "시간 절약" | 도메인별 큐레이션된 SQL 샘플·테이블이 핵심 |
| Pinterest (2024.4) | Querybook 내장 Text-to-SQL + RAG 테이블 발견 | 첫 시도 수용률 20→40%+, 작성 속도 35% 개선 | 메타데이터 문서화 시 테이블 적중률 90% (2.25배) |
| LinkedIn SQL Bot (2024.12) | 지식 그래프(스키마+쿼리 로그+도메인 지식) + 멀티에이전트 + 자가수정 | 사용자 ~95%가 정확도 "Pass" 이상 평가 | 플랫폼 내장(DARWIN)으로 채택률 5~10배 |
| Snowflake Cortex Analyst (2024.8) | 시맨틱 모델(YAML) + 멀티에이전트 | 실사용 케이스 SQL 정확도 90%+ | 동일 평가에서 GPT-4o 단발 생성은 51% — 시맨틱 모델이 약 2배 차이 |
| Databricks AI/BI Genie (2024) | Genie Space + Unity Catalog 메트릭 | 실무 사례: raw 50% → 시맨틱 큐레이션 후 90% | 거버넌스된 메트릭 정의가 정확도의 지렛대 |
| Anthropic (2026.6) | 범용 에이전트(Claude Code) + 4계층 스택 + 스킬 | 쿼리 95% 자동화, 정확도 ~95% (일부 99%) | 스킬 콜로케이션 + ablation 문화 + 교정 수확 루프 |
공통 패턴이 보이는가? 여섯 회사 모두 (1) raw 스키마 직접 노출은 실패했고, (2) 큐레이션된 컨텍스트 계층을 만들었으며, (3) 평가 기반 검증으로 수렴했다.
그럼에도 Anthropic 사례가 한 단계 더 나아간 지점이 있다:
- 전용 Text-to-SQL 도구가 아니라 범용 에이전트(Claude Code) + 마크다운 스킬이라는 훨씬 단순하고 이식 가능한 형태라는 것
- 정확도 유지를 일회성 프로젝트가 아니라 PR 단위의 일상 규율(데이터 모델 PR의 90%가 스킬 수정 동반)로 만들었다는 것
- 그리고 무엇이 효과 없었는지를 수치와 함께 공개했다는 것 — 이건 업계 전체에 몇 달치 시행착오를 절약해주는 선물이다
제7장: 세 가지 시선 — 열광, 냉담, 그리고 날카로운 비판
발표에 대한 반응은 흥미롭게 갈렸다.
LinkedIn의 데이터 커뮤니티는 열광했다. Dagster 출신의 데이터 인플루언서 Pedram Navid는 "Anthropic 데이터 팀이 얼마나 대단한지 말로 다 표현할 수 없다 — 질문에 대한 답을 마찰 없이 얻을 수 있게 만들었다"고 썼고, 댓글에는 "AI 도입과 무관하게 메트릭 정의·거버넌스·데이터 품질이라는 근본 과제는 그대로"라는 공감이 이어졌다.
Hacker News는 냉담했다. 프런트페이지 진입 실패, 댓글 1개("Uber가 이미 했다"). 이 비대칭 자체가 시사적이다 — 일반 개발자에게는 "또 하나의 사내 자랑"으로 보이지만, 데이터 실무자에게는 자신들이 매일 싸우는 문제의 해부도였던 것이다.
가장 날카로운 비판은 Genloop의 Ayush Gupta에게서 나왔다. Spider 2.0 리더보드 1위 기업의 CEO답게 구체적이다:
⚠
"95%는 진짜 비용을 가린다"
95%는 시니어 데이터 팀이 수개월 큐레이션한 정상상태(steady-state) 수치다. 콜드스타트는 21%였고, 그 74%p의 간극은 모델이 아니라 사람이 메웠다. "마케팅으로 취급해야지 측정치로 취급하면 안 된다."
⚠
"대부분 기업에는 Anthropic의 전제 조건이 없다"
보통 기업에는 "한 번도 문서화된 적 없는 3년치 분석가 관습"이 쌓여 있다. 15년 된 데이터 자산에 이 청사진을 적용하면 "출시일 없는 영구 엔지니어링 프로그램"이 된다. 콜로케이션도 단일 팀 전제 — DE와 분석 조직이 분리된 회사에선 한 스프린트 만에 깨진다.
⚠
"프롬프트는 접근 제어가 아니다"
스킬 지시문으로는 row-level 접근 제어를 할 수 없다. 규제 데이터에는 시스템 레벨 통제가 필요하다. 그리고 토큰 비용 — Anthropic의 자원은 일반적이지 않다.
공정한 비판이고, 새겨들을 가치가 있다. 다만 흥미로운 점: Gupta조차 방향 자체에는 동의한다. 그가 "맞았다"고 인정한 목록 — 컨텍스트 엔지니어링이 모델 선택보다 중요하다, raw 쿼리 코퍼스 검색은 실패한다, 시맨틱 레이어를 강제 우선하라, 유지보수가 정확도다 — 은 사실상 이 글의 핵심 주장 전부다. 논쟁은 "이게 맞는 방향인가"가 아니라 "누가 이 비용을 감당할 수 있는가"에 있다.
중국 테크 미디어 36Kr의 표현이 이 글의 본질을 가장 잘 요약했는지도 모른다: "95%는 만들어지는 것이 아니라 길러지는 것이다(nurtured)."
제8장: 실무 적용 가이드 — 내일부터 무엇을 할 것인가
Anthropic의 조언은 명확하다. 제로에서 시작한다면:
소수의 정규 데이터셋, 몇십 개의 오프라인 평가, 얇은 지식 스킬 — 이 세 가지가 이득의 대부분을 가져온다. 이 글의 나머지 전부는 그것들을 갖춘 뒤에 추가한 것이다.
1단계: 가장 많이 받는 질문 도메인 하나를 고른다 (예: 매출, 가입)
↓
2단계: 그 도메인의 정규 데이터셋을 만들고 유사 중복을 폐기한다
↓
3단계: 질문-정답 쌍 수십 개로 오프라인 평가 세트를 만든다 (스냅샷 고정)
↓
4단계: 얇은 지식 스킬을 작성한다 — "이 메트릭은 여기, 이 함정은 이렇게"
↓
5단계: 평가 통과율 ~90% 전까지 공개하지 않는다 (출시 게이트)
↓
6단계: 데이터 모델 PR에 스킬 문서 수정을 묶는다 (콜로케이션 + 리뷰 훅)
조직에 맞는 답을 찾기 위한 5가지 질문
모든 관행이 모든 팀에 맞는 것은 아니다. Anthropic이 제안하는 정렬 질문:
- 오늘의 정답이 얼마나 중요한가, 미래의 정답이면 충분한가? — 모델은 빠르게 발전한다. 현 모델의 약점을 보완하는 인프라를 잔뜩 지었는데 다음 모델에서 무의미해지는 경우를 자주 본다. 모델 개선을 기다리는 쪽이 오버헤드는 훨씬 적다 — 단, 회사의 리스크 허용도와 맞아야 한다.
- 비즈니스 복잡도는 어떻게 변할 것인가? — 데이터가 적고 소비자가 소수이고 데이터 모델이 단순하게 유지될 것 같다면, 이 글의 프로세스 상당수는 과잉이다.
- 출력의 청중은 얼마나 기술적인가? — 틀린 답을 알아챌 수 있는 데이터 사이언티스트가 청중이라면 오류 허용도가 높아도 된다. 데이터 모델을 전혀 모르는 청중이라면 적대적 리뷰 같은 비싼 검증이 필요하다.
- 정확도 향상에 얼마를 지불할 것인가? — 적대적 검증은 정확도를 유의미하게 올리지만 토큰 +32%, 지연 +72% 같은 가격표가 붙는다.
- 접근 제어와 내부 데이터 프라이버시에 대한 입장은? — 에이전트는 컨텍스트가 넓을수록 성능이 좋아지지만, 광범위한 데이터 접근은 대부분 회사의 거버넌스 기조와 충돌한다. 이 답이 "하나의 에이전트"냐 "여러 개의 스코프 제한 에이전트"냐를 결정한다.
스킬 파일 스켈레톤 (원문 부록 기반)
Anthropic이 공개한 메인 웨어하우스 스킬의 뼈대다. 그대로 베끼라는 것이 아니라, 어떤 종류의 섹션을 적어둘 가치가 있는지 보여주는 지도다:
hljs language-yaml
---
name: warehouse-skill
version: x.y.z
description: "IF 사용자가 [비즈니스 도메인 목록] 질문으로 회사 데이터 웨어하우스를
조회하려 하면 — THEN 이 스킬을 호출. [인접 엔지니어링 작업]이나
데이터 웨어하우스와 무관한 질문에는 호출하지 말 것."
---
레퍼런스 문서의 뼈대는 더 단순하다:
hljs language-markdown
# [도메인] 테이블
## Quick Reference
- 비즈니스 맥락: 이 도메인이 일상 언어로 무엇을 의미하는가
- 엔티티 그레인: 한 행이 무엇을 나타내는가
- 표준 위생 필터: 이 도메인의 모든 쿼리가 적용하는 필터
## Dimensions
- 핵심 차원의 인코딩 방식, 같은 개념이 테이블마다 다르게 불리는 경우
## Key Tables
### [table_name]
- 그레인 / 범위·제외 / 사용법(언제 쓰고 언제 쓰지 말지, 조인 키, 필수 필터)
## Gotchas
- 시니어 분석가가 경고할 오답 패턴들
## Best Practices / Common Query Patterns
- 기본 선택지, 표준 컷, 쿼리 형태 자체가 어려운 문제의 워크드 패턴
## Cross-References
- 인접 질문을 소유한 이웃 도메인 문서
한국 기업을 위한 현실적 체크포인트
코어닷투데이의 관점에서 몇 가지를 덧붙인다:
- 시맨틱 레이어가 없다고 시작을 미루지 마라. Anthropic도 "정규 데이터셋 몇 개 + 평가 수십 개 + 얇은 스킬"이 이득의 대부분이라고 말한다. dbt를 쓰고 있다면 MetricFlow가, Snowflake라면 Cortex Analyst의 시맨틱 모델이 출발점이 될 수 있다. 핵심은 도구가 아니라 "매출"의 정의를 하나로 합의하는 정치적 작업이다 — 그건 어떤 AI도 대신해주지 않는다.
- 콜드스타트 21%를 그대로 겪지 마라. Genloop의 비판이 맞다 — Anthropic의 95%는 길러진 숫자다. 하지만 거꾸로 보면, 가장 질문이 몰리는 도메인 하나만 길러도 그 도메인의 애드혹 요청은 사라진다. 전사 적용이 아니라 단일 도메인 수직 적용으로 시작하라.
- 평가 세트가 곧 자산이다. 스테이크홀더의 교정 한 마디가 평가 케이스가 되고, 평가 케이스가 문서 수정이 되고, 문서 수정이 정확도가 되는 루프 — 이 루프의 시동을 거는 데는 수십 개의 질문-정답 쌍이면 충분하다. 분석가가 슬랙에서 받은 질문을 한 달만 모아도 만들 수 있다.
- 접근 제어는 시스템 레벨에서. 스킬 지시문은 가드레일이지 보안 경계가 아니다. 개인정보보호법 적용 데이터라면 에이전트가 닿을 수 있는 뷰 자체를 제한하라.
마치며: 데이터 팀의 일은 사라지는 게 아니라 이동한다
이 글의 표면적 메시지는 "Claude가 분석 쿼리의 95%를 처리한다"이지만, 행간의 메시지는 정반대에 가깝다. 이 시스템에서 사람의 일은 줄어든 것이 아니라 옮겨갔다.
전
예전의 데이터 팀
애드혹 SQL 요청 처리에 시간의 50~70%를 소모. "지난달 그 숫자 다시 뽑아주세요"의 무한 루프.
후
지금의 데이터 팀
정의를 큐레이션하고(시맨틱 레이어), 지식을 증류하고(스킬·참조 문서), 실험을 설계하고(ablation·평가), 루프를 감시한다(교정 수확). 그리고 남는 시간에 — 인과 모델링, 예측, 머신러닝.
✓
핵심 전환
"질문에 답하는 사람"에서 "답하는 시스템을 기르는 사람"으로. 95%는 만들어지는 것이 아니라 길러진다.
60년 전 LUNAR가 월석 데이터에 자연어로 답하려 한 이래, "누구나 데이터에 질문할 수 있게 하자"는 꿈은 규칙 기반 시스템으로, OLAP 큐브로, 드래그앤드롭 BI로, 검색형 분석으로, 그리고 1세대 자연어 질의로 — 다섯 번쯤 모습을 바꿔가며 좌절해왔다. 매번 실패의 원인은 같았다. 기술이 자연어를 이해하지 못해서가 아니라, 조직이 자기 데이터의 의미를 하나로 정의하지 못해서.
LLM은 이 문제의 앞부분(자연어 이해와 SQL 생성)을 마침내 풀었다. 그러자 뒷부분 — 모호성, 신선도, 검색 — 이 그대로 드러났다. Anthropic의 기여는 이 뒷부분에 이름을 붙이고, 계층별 해법을 설계하고, 무엇이 효과 있고 없는지를 측정해서 공개한 것이다.
마지막 줄로 이 글의 결론을 요약하면:
우리의 가장 큰 이득은 세 가지 실패 모드 각각을 공략한 데서 왔다: 모호성을 하나의 거버넌스된 답으로 붕괴시키고, 그 답을 쉽게 발견 가능하게 만들고, 둘 중 하나가 낡으면 그것을 알아차리는 것. — Anthropic 원문
도구는 갖춰졌다. Claude Code도, Skills도, MCP도, 시맨틱 레이어 기술도 모두 공개되어 있다. 남은 것은 각 조직이 자기 데이터의 의미를 정의하는 — 미룰 수 없게 된 — 숙제다.
참고 자료
원문 및 Anthropic 관련
Text-to-SQL 역사와 벤치마크
- Seq2SQL (arXiv:1709.00103) — Zhong et al., Salesforce (2017)
- Spider (arXiv:1809.08887) — Yu et al., Yale (2018)
- BIRD (arXiv:2305.03111) — Li et al., NeurIPS (2023) · 리더보드
- Spider 2.0 (arXiv:2411.07763) — Lei et al., ICLR 2025 Oral · 리더보드
- Text2SQL is Not Enough: TAG (arXiv:2408.14717) — Biswal et al., Berkeley+Stanford (2024)
시맨틱 레이어와 BI 역사
업계 사례
- QueryGPT — Uber Engineering (2024)
- How we built Text-to-SQL at Pinterest — Pinterest Engineering (2024)
- Practical text-to-SQL for data analytics — LinkedIn Engineering (2024)
반응과 비판




