블로그로 돌아가기
S3AWS스토리지오브젝트 스토리지클라우드보안
AWS S3 완전 정복: 인터넷의 하드디스크가 된 서비스의 모든 것
AWS의 첫 번째 서비스이자, 인터넷 인프라의 보이지 않는 기둥. S3가 왜 탄생했고, 어떻게 99.999999999%의 내구성을 달성하며, 전 세계 기업이 어떤 사고를 겪었고, 실무에서 어떻게 활용해야 하는지를 풀어본다.
코어닷투데이2026-01-1625분
AWS의 첫 번째 서비스이자, 인터넷 인프라의 보이지 않는 기둥. S3가 왜 탄생했고, 어떻게 99.999999999%의 내구성을 달성하며, 전 세계 기업이 어떤 사고를 겪었고, 실무에서 어떻게 활용해야 하는지를 풀어본다.
2006년 3월 14일, Amazon Web Services가 첫 서비스를 출시했다. EC2가 아니었다. S3(Simple Storage Service) 였다. EC2는 5개월 뒤인 8월에 출시됐다.
AWS의 역사가 S3에서 시작했다는 것은 상징적이다. 컴퓨팅보다 스토리지가 먼저 필요했다. 데이터를 저장할 곳이 없으면 컴퓨팅도 의미가 없기 때문이다.
18년이 지난 지금, S3는 수백 엑사바이트(EB)의 데이터를 저장하며, 수조 개의 객체를 관리한다. Netflix의 영화, Airbnb의 사진, NASA의 위성 데이터, 수많은 기업의 백업 — 인터넷에서 당신이 보는 데이터의 상당 부분이 S3에 저장되어 있을 가능성이 높다.
S3는 단순한 파일 저장소가 아니다. 웹 호스팅, 데이터 레이크, 백업, CDN 오리진, 로그 저장소, AI 학습 데이터 — 클라우드 아키텍처의 중력 중심이다.

2000년대 초반, 기업이 데이터를 저장하는 방식은 두 가지였다:
파일 스토리지 (NAS): 네트워크에 연결된 파일 서버. 폴더 구조로 파일을 관리한다. 가정에서 쓰는 NAS와 본질적으로 같다. 문제: 용량에 한계가 있고, 확장하려면 새 장비를 사야 한다. 수 테라바이트가 한계.
블록 스토리지 (SAN): 데이터를 고정 크기 블록으로 저장. 데이터베이스에 최적화. 빠르지만 비싸다. 수십~수백 테라바이트까지 가능하지만, 장비 비용이 수억 원.
두 방식 모두 물리적 한계가 있었다. 디스크가 꽉 차면 새 디스크를 사야 하고, 새 장비를 설치하는 데 수 주가 걸렸다. 그리고 결정적으로 — 데이터가 한 장소에 있으므로, 그 장소에 문제가 생기면 데이터를 잃는다.
Amazon은 이커머스 사업을 운영하면서 폭발적으로 증가하는 데이터와 씨름했다. 상품 이미지, 리뷰, 주문 기록, 로그 — 데이터는 끊임없이 늘어나는데, NAS와 SAN은 한계가 있었다.
Amazon 엔지니어들이 원한 것:
이 요구사항의 결합이 오브젝트 스토리지(Object Storage) 라는 새로운 패러다임을 만들었다.
S3의 오브젝트 모델은 극도로 단순하다:
photos/2026/vacation/sunset.jpg 같은 경로처럼 보이지만, 실제로는 하나의 플랫한 문자열이다. /는 그냥 키 이름의 일부photos/2026/vacation/은 폴더가 아니다. 실제 디렉토리 구조는 존재하지 않는다. 콘솔에서 폴더처럼 보이는 것은 키 이름의 /를 기준으로 시각적으로 그룹핑한 것일 뿐이다. 이것이 S3가 수조 개의 객체를 관리할 수 있는 이유 중 하나다 — 디렉토리 트리를 탐색할 필요가 없다.S3의 핵심 API는 4개뿐이다:
# 객체 저장
PUT /bucket-name/key
# 객체 조회
GET /bucket-name/key
# 객체 삭제
DELETE /bucket-name/key
# 객체 목록 조회
GET /bucket-name?list-type=2&prefix=photos/
이 단순한 API 위에 인터넷 인프라의 상당 부분이 구축되어 있다.
S3의 가장 유명한 수치: 99.999999999% (11 나인) 내구성. 이것은 1,000만 개의 객체를 S3에 저장하면, 10,000년에 1개를 잃을 확률이라는 뜻이다. 사실상 "데이터를 잃지 않는다"와 동의어다.
어떻게 이것이 가능한가?
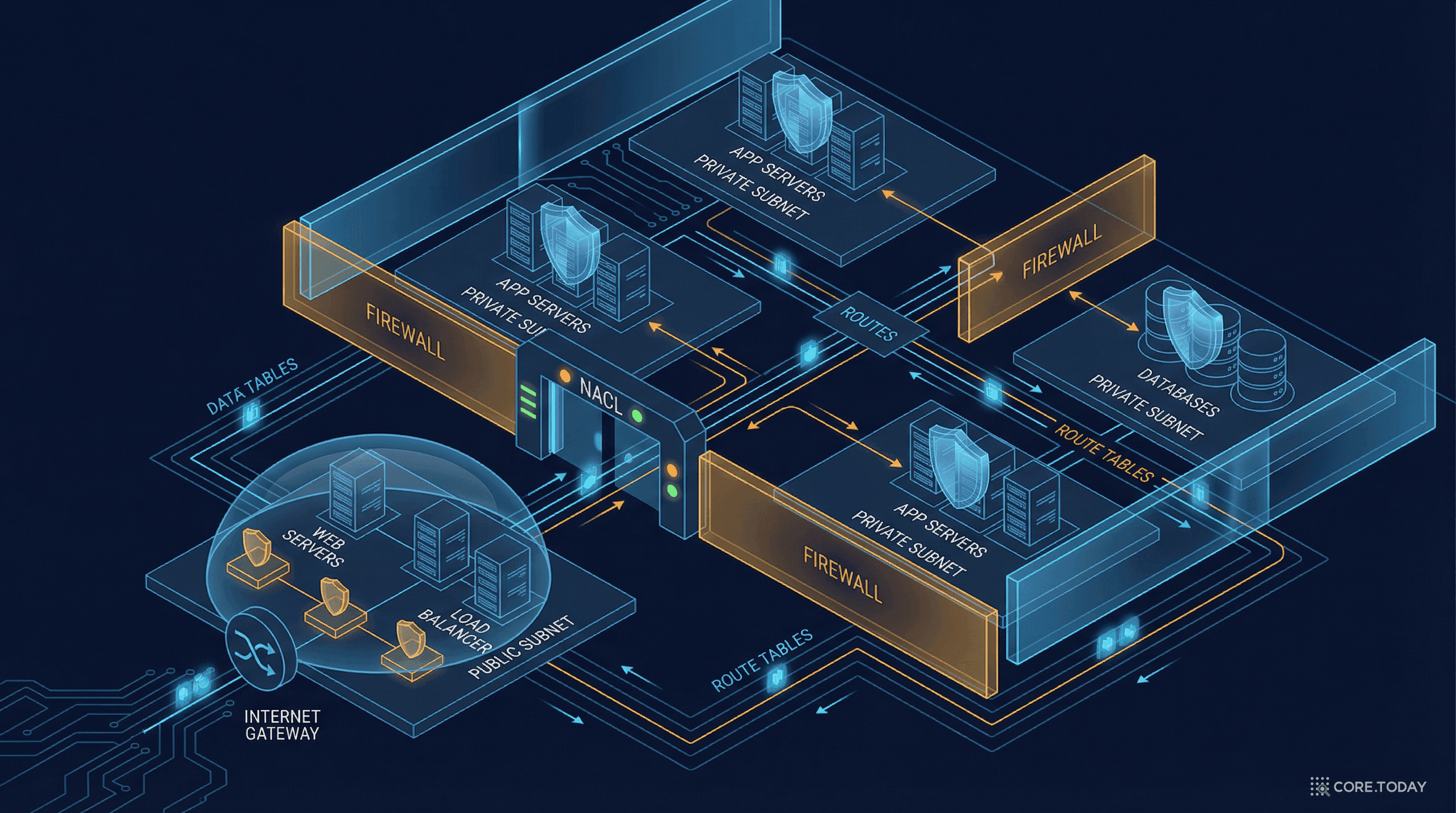
1. 자동 복제: 객체를 저장하면, S3는 같은 리전 내의 최소 3개 이상의 가용 영역(AZ)에 자동으로 복제한다. 각 AZ는 물리적으로 분리된 데이터센터다.
2. 데이터 무결성 검증: 모든 저장·전송 시 체크섬으로 데이터 손상을 감지한다. 손상이 발견되면 다른 복제본에서 자동으로 복구한다.
3. 디스크 장애 자동 복구: 디스크가 고장 나면 S3가 자동으로 다른 디스크에 데이터를 재복제한다. 관리자 개입 없이.
S3의 내부 아키텍처는 공개되지 않았지만, Amazon이 2007년 ACM SOSP에서 발표한 "Dynamo: Amazon's Highly Available Key-value Store" 논문이 중요한 단서를 제공한다.
Dynamo 논문의 핵심 원칙들 — 일관된 해싱, 복제, 버전 관리, 안티엔트로피(자동 복구) — 은 S3의 설계에도 반영된 것으로 알려져 있다. 특히 "항상 쓰기 가능(always writeable)" 원칙과 "최종적 일관성(eventual consistency)" 모델은 S3의 초기 설계를 이해하는 데 핵심적이다.
모든 데이터가 같은 빈도로 접근되지 않는다. S3는 접근 패턴에 따른 다양한 스토리지 클래스를 제공한다.
| 클래스 | 저장 비용 (GB/월) | 조회 비용 | 접근 패턴 | 비유 |
|---|---|---|---|---|
| Standard | $0.025 | 낮음 | 자주 접근 | 책상 위 서류 |
| Intelligent-Tiering | $0.025~$0.005 | 없음 | AWS가 자동 분류 | AI 비서가 정리 |
| Standard-IA | $0.0138 | 중간 | 월 1~2회 접근 | 서랍 속 서류 |
| One Zone-IA | $0.011 | 중간 | 드물게 접근, 재생성 가능 | 복사본은 한 곳만 |
| Glacier Instant | $0.005 | 높음 | 분기 1회, 즉시 필요 | 보관 캐비닛 |
| Glacier Flexible | $0.0045 | 높음 + 복원 시간 | 연 1~2회, 수 시간 대기 가능 | 창고 |
| Glacier Deep Archive | $0.002 | 매우 높음 + 12시간 대기 | 거의 접근 안 함, 규정 보관 | 지하 금고 |
{
"Rules": [
{
"ID": "ArchiveOldLogs",
"Filter": { "Prefix": "logs/" },
"Status": "Enabled",
"Transitions": [
{ "Days": 30, "StorageClass": "STANDARD_IA" },
{ "Days": 90, "StorageClass": "GLACIER" },
{ "Days": 365, "StorageClass": "DEEP_ARCHIVE" }
],
"Expiration": { "Days": 2555 }
}
]
}
이 정책: 로그 파일을 30일 후 IA로, 90일 후 Glacier로, 1년 후 Deep Archive로, 7년 후 삭제. 규제 준수(7년 보관)와 비용 최적화를 동시에 달성한다.
S3의 보안 역사는 클라우드 보안의 축약판이다. 수많은 기업이 S3 설정 실수로 대규모 데이터 유출을 겪었다.
이 사고들의 공통점: S3 버킷을 "Public(공개)"으로 설정한 것. S3 자체의 결함이 아니라 설정 실수였다. AWS는 이후 보안 기본값을 대폭 강화했다.
2026년 현재, S3의 보안은 여러 레이어로 구성된다:
1. Block Public Access (2018~)
버킷과 계정 수준에서 공개 접근을 원천 차단하는 설정. 2023년 4월부터 새로 생성되는 모든 버킷에 기본 활성화. 실수로 공개하는 것이 구조적으로 어려워졌다.
2. 버킷 정책과 IAM
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": "arn:aws:s3:::my-bucket/*",
"Condition": {
"Bool": { "aws:SecureTransport": "false" }
}
}
]
}
이 정책: HTTPS가 아닌 요청은 모두 차단. 전송 중 암호화를 강제한다.
3. 서버사이드 암호화 (SSE)
S3는 저장 시 데이터를 자동으로 암호화한다. 2023년 1월부터 모든 새 객체에 SSE-S3 암호화가 기본 적용된다. 추가 설정이나 비용 없이.
4. S3 Object Lock
데이터를 지정된 기간 동안 삭제도 수정도 불가능하게 잠그는 기능. 금융 규제, 법적 보존 의무에 대응한다. 관리자조차 삭제할 수 없다.
S3 버킷에 HTML, CSS, JS 파일을 올리면 웹사이트가 된다. EC2 인스턴스 없이. CloudFront(CDN)와 결합하면 전 세계에서 빠르게 접근 가능한 정적 사이트를 수 분 만에 배포할 수 있다.
Next.js, React, Vue로 빌드한 정적 사이트를 S3 + CloudFront에 올리는 것이 2026년 현재 가장 흔한 프론트엔드 배포 패턴 중 하나다.
데이터 레이크(Data Lake) — 모든 종류의 데이터를 원본 그대로 중앙에 저장하는 저장소. S3가 사실상의 표준 데이터 레이크 스토리지다.
왜 S3인가:
온프레미스 데이터의 백업 대상으로 S3가 가장 많이 사용된다:
이전 Lambda 글에서 다뤘듯이, S3는 Lambda의 가장 대표적인 이벤트 소스다:
AI 모델 학습에는 대량의 데이터가 필요하다. 수 TB~PB 규모의 학습 데이터를 S3에 저장하고, SageMaker나 EC2 GPU 인스턴스가 직접 읽어 학습한다.
S3 비용은 생각보다 복잡하다:
| 항목 | Standard 기준 | 함정 |
|---|---|---|
| 저장 | $0.025/GB/월 | 삭제하지 않으면 계속 누적 |
| PUT/POST 요청 | $0.005/1,000건 | 작은 파일 대량 업로드 시 주의 |
| GET 요청 | $0.0004/1,000건 | CDN 없이 직접 조회 시 주의 |
| 데이터 전송 (아웃) | $0.09/GB (첫 10TB) | 가장 큰 비용 요소일 수 있음 |
| 데이터 전송 (인) | 무료 | 업로드는 항상 무료 |
1. 라이프사이클 정책 반드시 설정
오래된 데이터를 자동으로 저렴한 클래스로 이동. 설정 안 하면 모든 데이터가 Standard 요금으로 계속 과금된다.
2. 불필요한 버전 관리 정리
Versioning을 켜면 삭제해도 이전 버전이 남는다. 오래된 버전을 자동 삭제하는 라이프사이클 정책을 추가하라.
3. 멀티파트 업로드 사용
100MB 이상의 파일은 멀티파트 업로드를 사용하라. 실패 시 전체를 다시 올릴 필요 없이 실패한 파트만 재전송. 미완료 멀티파트 업로드를 자동 삭제하는 정책도 설정하라 — 미완료 파트가 쌓여 비용이 발생한다.
4. S3 Storage Lens 활용
계정 전체의 S3 사용 패턴을 분석하는 대시보드. 어떤 버킷이 비용을 많이 쓰는지, 어떤 데이터가 접근되지 않는지 한눈에 파악할 수 있다.
Netflix는 수천만 시간 분량의 마스터 영상을 S3에 저장한다. 각 영상은 수십 가지 해상도와 코덱으로 인코딩되어, 각각 별도의 S3 객체로 저장된다. 원본은 Glacier에 아카이브하고, 인코딩된 스트리밍 파일은 Standard에서 CloudFront로 서빙한다.
NASA의 지구 관측 데이터, 우주 탐사 데이터가 S3에 저장된다. Petabyte(PB) 단위의 위성 이미지, 기후 데이터, 천문 관측 데이터를 연구자들이 S3에서 직접 분석한다. AWS의 Open Data 프로그램을 통해 일부는 무료로 공개되어 있다.
Slack에서 공유되는 모든 파일, 이미지, 문서가 S3에 저장된다. 하루에 수억 건의 파일이 업로드되고 다운로드된다.
S3 Select는 객체 내부의 데이터를 서버사이드에서 필터링한다. 1GB의 CSV에서 특정 컬럼만 필요할 때, 전체를 다운로드하지 않고 S3에서 필터링한 결과만 전송한다. 전송 비용과 시간을 대폭 절감.
S3 Object Lambda는 객체를 읽을 때 Lambda 함수가 자동 실행되어 데이터를 변환한다. 같은 원본 데이터를 읽는 앱이 여러 개인데, 각각 다른 형식이 필요할 때 유용하다.
2023년 출시. 단일 AZ에 저장하지만 한 자릿수 밀리초 지연 시간을 보장한다. AI/ML 학습처럼 초저지연이 필요하고 내구성은 한 단계 낮아도 되는 워크로드에 적합.
2024년 프리뷰. S3에 Apache Iceberg 형식의 테이블을 네이티브로 저장하고 쿼리한다. 데이터 레이크와 데이터 웨어하우스의 경계가 더 흐려진다.
S3를 이해하면 클라우드 아키텍처의 패턴이 보인다. S3는 단순한 스토리지가 아니라 클라우드의 중력 중심이다.
AWS의 첫 서비스가 S3였다는 것은 우연이 아니다. 데이터가 먼저이고, 컴퓨팅은 그 다음이다. 이 순서는 18년이 지난 지금도 변하지 않았다. AI 시대에도 마찬가지다 — 데이터가 없으면 AI도 없다.
코어닷투데이의 AI 서비스에서도 S3는 기반 인프라다. 학습 데이터 저장, 모델 아티팩트 관리, 추론 결과 아카이브, 사용자 업로드 처리 — 이 모든 데이터 흐름의 중심에 S3가 있다.